540만 건 부동산 검색 엔진 구축기: OpenSearch 도입부터 성능 최적화까지
목차
- 1. 배경: 기존 검색의 한계
- 기존 구조
- 한계
- 2. OpenSearch 도입
- 기술 선택
- 검색 정책 수립
- 검색 범주 설계
- 3. 인덱스 설계
- 필드 구조
- 4. 1차 배포: 일단 돌아가게 (2026.03)
- 1차 배포 쿼리 구조
- 1차 배포의 한계
- 5. 중간 개선: ngram 도입과 쿼리 구조 변경
- ngram 도입
- script sort 제거와 정렬 절충
- 6. 벤치마크 기반 성능 최적화
- 벤치마크 환경
- 시도 1: scriptscore로 함수 17개를 1개로 줄이기
- 시도 2: edgengram으로 prefix 쿼리 대체
- 시도 3: source 필터링 + 쿼리 구조 전면 전환
- 7. 2차 배포: 최종 결과 (2026.04)
- 3단계 변화 요약
- 8. 교훈
- 이론적 병목 ≠ 실제 병목
- 왜 이론과 실측이 달랐을까?
- 기술적 교훈
- 협업에서의 반성
- 실제 검색 결과
- 마무리
DB + 공공 API 기반 검색의 한계를 극복하기 위해 OpenSearch를 도입하고, 540만 건 부동산 데이터에 대한 자동완성 검색 엔진을 설계·구축·최적화한 전체 과정을 공유한다.
1. 배경: 기존 검색의 한계
2025년 10월, 전국 거주지 정보를 정리하면서 고객이 원하는 집을 빠르게 탐색할 수 있는 검색 기능이 필요해졌다. 당시 팀 내에 Elasticsearch를 다뤄본 사람이 없었고, 빠르게 출시해야 하는 상황이라 학습할 시간도 없었다. 그래서 일단 돌아가는 방식으로 구현했다.
기존 구조
- 건물명 검색: DB에서 LIKE 검색
- 주소 검색: juso.go.kr 공공 API 호출
- 분기 처리: regex로 입력값이 건물명인지 주소인지 판단
한계
세 가지 문제가 쌓였다.
regex 분기 오류: regex를 벗어나는 도로명이 입력되면 juso.go.kr로 가야 할 키워드가 DB로 전달되거나, 반대로 건물명이 공공 API로 넘어가는 경우가 간헐적으로 발생했다.
정렬 제어 불가: juso.go.kr의 응답은 API가 반환하는 순서 그대로였다. 기획팀이 원하는 지역 우선순위나 건물명 길이 기반 정렬을 적용할 방법이 없었다.
성능 한계: 540만 건에 대한 LIKE 검색은 인덱스를 아무리 잘 걸어도 한계가 있었다. 자동완성처럼 타이핑할 때마다 요청이 들어오는 패턴에서는 더욱 그랬다. 특히 "아파트", "주택", "빌라"처럼 전국적으로 광범위하게 사용되는 키워드는 수백만 건이 매칭되어 응답 시간이 더욱 길어졌다.
2. OpenSearch 도입
기술 선택
팀 내부 논의 끝에 팀장님이 Elasticsearch가 아닌 AWS OpenSearch를 선택했다. 이유를 몇 가지로 정리하면:
- 관리 부담 최소화: 클러스터 인프라 운영과 보안 패치를 AWS가 담당하므로 소규모 팀이 검색 엔진 인프라에 시간을 쓰지 않아도 된다.
- Elasticsearch와 호환: Elasticsearch 7.10 기반 Fork라 기존 ES 생태계의 지식과 라이브러리를 그대로 활용할 수 있다.
- 라이선스 리스크 없음: Elastic이 7.11부터 SSPL로 라이선스를 변경했는데, OpenSearch는 Apache 2.0을 유지하므로 상업 서비스에서 제약이 없다.
- nori 한국어 형태소 분석기 지원: 한글 토큰화를 위한 nori 플러그인이 기본 탑재되어 있어 별도 설치 없이 사용 가능하다.
팀장님이 먼저 OpenSearch 클러스터를 생성하고, 회사 DB의 건물 데이터를 1:1 매핑하여 인덱스에 밀어넣은 상태까지 셋업해두셨다. 튜닝이나 검색 쿼리는 없는, 껍데기 상태였다.
이걸 이어받아 검색 엔진을 전담으로 개발하게 됐다. 우선순위는 명확했다.
- 건물명 + 도로명 검색을 분기 없이 하나의 서비스에서 처리 — 기존 regex 분기 구조를 없애고 OpenSearch 단일 쿼리로 해결
- 기획팀이 의도하는 정렬 순서 보장 — 지역 우선순위, 건물명 길이 등 커스텀 정렬 로직 구현
- 빠른 응답 성능 — "아파트", "주택"처럼 수백만 건이 매칭되는 키워드에서도 자동완성 수준의 응답 속도 확보
검색 정책 수립
기획팀에서 원한 검색 정렬 순위는 다음과 같았다:
1. 키워드 100% 완전 일치가 최우선
2. 키워드가 건물명 맨 앞에 있는(prefix) 검색어가 그 다음
3. 건물명이 짧은 순
4. 건물명 사전순
5. 지정한 지역순 (서울 > 경기 > 인천 > ...)검색 범주 설계
| 범주 | 예시 |
|---|---|
| 단지명/건물명 완전 일치 | "청운동 라임카운티" |
| 단지명/건물명 prefix | "청운동", "라임" |
| 공백 포함 키워드 | "라임카운티 청운동" (순서 변경 대응) |
| 도로명 정확 일치 | "사가정로", "사가정로 232" |
| 지역+시군구+키워드 조합 | "서울 동대문구 사가정로 232" |
3. 인덱스 설계
Text(형태소 분석) vs Keyword(완전 일치) 이중 필드 전략을 채택했다:
name → text (형태소 분석, match 검색용)
name.keyword → keyword (완전 일치, prefix 검색용)
name_normalized → keyword (정규화, 띄어쓰기 예외 대응)normalized 필드 도입 이유: "서울특별시 강남구 테헤란로 212"에서 "테헤란로"와 "212" 사이의 띄어쓰기 유무에 따라 검색 결과가 달라질 수 있다. 모든 공백/특수문자를 제거한 normalized 필드를 별도로 두어 이런 예외를 흡수했다.
필드 구조
| 필드 유형 | 타입 | 용도 |
|---|---|---|
| 건물명 | text + keyword | 형태소 검색 + 완전 일치 |
| 건물명 정규화 | keyword | 띄어쓰기 예외 대응 |
| 도로명 정규화 | keyword | 도로명 prefix 매칭 |
| 지번 정규화 | keyword | 지번 prefix 매칭 |
| 통합 검색 텍스트 | text | 모든 필드 합친 통합 검색 |
| 지역 우선순위 | integer | 기획팀이 정의한 지역 순서를 정수로 저장 |
4. 1차 배포: 일단 돌아가게 (2026.03)
당시 OpenSearch를 처음 대면하는 수준이었다. 공부가 부족한 상태에서 개발을 시작하다 보니 쿼리 구조가 상당히 무거웠다.
1차 배포 쿼리 구조
텍스트 검색은 function_score + bool(should) 7개 절로 구성했다. 건물명 형태소 매칭, 통합 텍스트 매칭, 건물명/도로명/지번의 정규화 prefix 매칭 등이다. function_score에 6개 함수를 추가하여 건물명 완전 일치, 정규화 일치, prefix 일치 순으로 가중치를 부여했다.
문제는 정렬이었다. 기획팀이 원하는 정렬 순서를 보장하기 위해 8단계 Painless script sort를 사용했다:
1. 건물명 존재 여부
2. 건물명-키워드 매칭 여부
3. 매칭 타입 (정확 > prefix)
4. 건물명 길이순
5. 건물명 사전순
6. 지역 우선순위
7. 도로명 prefix 매칭 (건물명이 없을 때)
8. 도로명 사전순매 요청마다 모든 매칭 문서에 대해 8개의 Painless 스크립트를 실행하는 구조였다. 문서 수가 많은 키워드일수록 성능 부담이 컸다.
1차 배포의 한계
script sort 성능 부담: 8단계 스크립트가 문서마다 실행되니, 매칭 문서가 많은 키워드에서 응답이 느렸다.
중간 매칭 미지원: ngram이 없었기 때문에 "하늘채빌딩"을 "늘채"로 검색하면 결과가 나오지 않았다.
_source 필터링 없음: 응답에서 인덱스의 전체 필드를 반환하고 있었다.
그럼에도 불구하고, 애초에 해결하려던 문제들 — regex 분기 오류, 정렬 제어 불가, LIKE 검색 성능 — 은 해소된 상태였다. DB 조회 + juso.go.kr 조회에 비해서는 더 나은 성능을 보장했고, 간헐적인 분기 오류도 사라졌다. 1차 목표를 달성한 것으로 보고 배포를 진행했다.
5. 중간 개선: ngram 도입과 쿼리 구조 변경
1차 배포 이후 OpenSearch를 본격적으로 공부하면서, 쿼리 구조를 단계적으로 개선해나갔다.
ngram 도입
중간 매칭 문제를 해결하기 위해 ngram 분석기를 인덱스에 추가했다. min_gram=2, max_gram=3으로 설정하면 "하늘채빌딩"이 "하늘", "늘채", "채빌", "빌딩" 등의 토큰으로 분해되어 "늘채"로도 검색이 가능해진다.
script sort 제거와 정렬 절충
8단계 Painless script sort를 제거하고, 스코어링 자체로 정렬을 반영하는 구조로 전환했다. 지역 우선순위는 function_score의 filter + weight 구조로, 건물명 길이는 linear decay로 반영했다.
다만 이 과정에서 기획팀의 정렬 정책을 완전히 구현하지는 못했다. 성능을 위해 사전순 정렬을 제거하는 등의 절충이 있었고, 정렬 순서의 세부 우선순위도 1차 배포와 달라진 부분이 있었다. 이 부분은 뒤에서 다시 다룬다.
이 시점의 쿼리 구조는 다음과 같다:
function_score
├── query: bool
│ ├── filter: 건물 유형 필터
│ └── should (minimum_should_match=1):
│ ├── L1: 건물명 완전 일치 — term
│ ├── L2: 건물명 prefix — prefix
│ ├── L2.5: 건물명 ngram — match(ngram)
│ ├── L3: 형태소 매칭 — match(nori)
│ ├── L4a: 도로명 prefix — prefix
│ ├── L4b: 지번 prefix — prefix
│ └── L4c: 주소 ngram — match(ngram)
└── functions:
├── 17개 지역 우선순위 필터 (지역 가산점)
└── 1개 linear decay (건물명 길이 가산점)1차 배포의 6개 function_score 함수가 18개(17개 지역 필터 + 1개 decay)로 늘어난 대신, 8단계 script sort가 사라졌다. 중간 매칭 문제도 해결됐다. 하지만 응답 시간이 여전히 100~150ms 수준이었다. 업계에서 자동완성은 보통 10~30ms를 기대한다.
6. 벤치마크 기반 성능 최적화
위 중간 개선 버전을 기준으로 벤치마크를 실행했다.
벤치마크 환경
- AWS OpenSearch dev 환경, 540만 건 실제 데이터
- 단일 요청 기준 측정 (동시 요청 없음)
- warm cache 상태 (벤치마크 전 동일 쿼리로 캐시 워밍)
- 41개 키워드 × 10회 반복, 7개 카테고리
- 측정값은 10회 평균
- Python 벤치마크 스크립트로 자동화
중간 개선 버전의 쿼리 구조를 분석해서 세 가지 성능 병목 가설을 세웠다:
| 병목 | 가설 |
|---|---|
| A. prefix 쿼리 6개 | 고카디널리티 keyword 필드의 prefix는 비용이 클 수 있다 |
| B. function_score 함수 18개 | 문서마다 18개 함수를 모두 순회 |
| C. ngram 인덱스 크기 | min_gram=2, max_gram=3 → 토큰 수 폭증 |
시도 1: script_score로 함수 17개를 1개로 줄이기
가장 쉬워 보이는 것부터. 18개 함수 중 17개 지역 우선순위 term 필터를 Painless 스크립트 1개로 통합했다.
// Before: 17개 필터
{ filter: { term: { rank: 1 } }, weight: ... }
{ filter: { term: { rank: 2 } }, weight: ... }
// ... ×17
// After: 1개 스크립트
{ script_score: { script: "순위 값 기반 가산점 계산 공식" } }결과: ±10ms. 네트워크 지터 범위 이내. 효과 없음.
OpenSearch의 filter cache가 term 필터 결과를 bitset으로 캐싱하고 있어서, 17개를 순회해도 비용이 매우 낮았다. Elastic 공식 문서가 script_score를 "비용이 큰 함수"로 분류한 것과도 일치하는 결과였다.
시도 2: edge_ngram으로 prefix 쿼리 대체
이론상 가장 확실한 개선안이었다.
keyword 필드에 대한 prefix 쿼리는 공식 문서에서도 expensive query로 분류된다. 540만 건이면 unique term 수가 상당하므로 이게 병목일 수 있다고 가정했다. edge_ngram 분석기로 인덱스 타임에 prefix 토큰을 미리 생성해두면 일반 term lookup으로 전환할 수 있다.
인덱스에 edge_ngram tokenizer + 6개 새 필드를 추가하고, 540만 건을 재인덱싱했다(약 2시간).
결과:
| 카테고리 | prefix (ms) | edge_ngram (ms) | 차이 |
|---|---|---|---|
| 건물명 정확 | 107.5 | 108.1 | +0.6 |
| 건물명 짧은 | 108.4 | 130.7 | +22.3 |
| 도로명 | 99.4 | 109.0 | +9.6 |
| 1글자 | 112.3 | 118.8 | +6.5 |
| 전체 평균 | ~101 | ~110 | +9ms (오히려 느려짐) |
역효과. edge_ngram 6개 필드를 추가하면서 인덱스 크기가 늘어났고, 모든 쿼리가 더 커진 인덱스에서 동작하면서 전체적으로 느려졌다.
540만 건 규모에서 prefix 쿼리는 실제 병목이 아니었다.
시도 3: _source 필터링 + 쿼리 구조 전면 전환
이론적 최적화에서 방향을 바꿔, 실질적 전송량 감소 + 쿼리 구조 단순화에 집중했다.
변경 내용:
- 쿼리 구조 전면 전환:
function_score+bool(should)→dis_max+constant_score5-tier 구조로 전환. function_score의 17개 지역 필터를 제거하고, 정렬 기준을_score desc → 건물명 길이 asc → 지역 우선순위 asc로 단순화했다. - _source 필터링: 응답에서 실제 사용하는 7개 필드만 반환. 기존에는 인덱스의 전체 원본 필드를 반환하고 있었고, 검색 보조용으로만 쓰이는 정규화 필드나 통합 텍스트 필드까지 불필요하게 포함되어 페이로드가 컸다.
- 1글자 검색 최적화: 1글자 입력 시에는 완전 일치와 prefix 매칭만 실행하도록 분기하여 불필요한 ngram/형태소 매칭을 건너뛴다.
결과 (중간 개선 버전 대비):
| 카테고리 | 중간 개선 (ms) | 최종 (ms) | 개선율 |
|---|---|---|---|
| 건물명 정확 | 107.5 | 94.9 | -12% |
| 건물명 prefix | 98.2 | 88.5 | -10% |
| 건물명 짧은 | 108.4 | 89.2 | -18% |
| 도로명 | 99.4 | 85.7 | -14% |
| 지번 | 99.7 | 89.7 | -10% |
| 1글자 | 112.3 | 67.5 | -40% |
| 전체 평균 | ~101 | ~83 | -17% |
모든 카테고리에서 일관되게 개선. 특히 1글자 검색은 실행되는 쿼리 절이 크게 줄면서 40% 빨라졌다.
7. 2차 배포: 최종 결과 (2026.04)
3단계 변화 요약
[1차 배포] function_score + bool(should) 7절 + 8단계 script sort
├── function_score: 6개 함수 (가중치 기반)
├── sort: 8단계 Painless script
├── ngram: 없음
└── _source: 전체 반환
[중간 개선] function_score + bool(should) 7절
├── function_score: 18개 함수 (17 지역 필터 + 1 decay)
├── sort: _score desc (script sort 제거)
├── ngram: 건물명 + 주소
└── _source: 전체 반환
[2차 배포] dis_max + constant_score 5-tier
├── T1: 건물명 완전 일치 — term
├── T2: 건물명 prefix — prefix
├── T3: 건물명 ngram 부분 일치 — match(ngram)
├── T4: 형태소 매칭 — match(nori)
├── T5: 주소 prefix + ngram — prefix + match(ngram)
├── sort: _score desc → 건물명 길이 asc → 지역 우선순위 asc
├── 1글자 검색 시 T1, T2만 실행
└── _source: 7개 필드만 반환| 항목 | 1차 배포 | 중간 개선 | 2차 배포 |
|---|---|---|---|
| 쿼리 구조 | function_score + should 7개 | function_score + should 7개 | dis_max + constant_score 5-tier |
| 정렬 | 8단계 Painless script sort | _score desc | _score desc + 필드 2개 |
| function_score 함수 | 6개 | 18개 (17+1) | 0개 |
| ngram | 없음 | 건물명 + 주소 | 건물명 + 주소 |
| 중간 매칭 | 미지원 | 지원 | 지원 |
| _source 필터링 | 없음 | 없음 | 7개 필드만 |
| 평균 응답 시간 | 측정 없음 | ~101ms | ~83ms (17%↓) |
1차 배포 시점에는 벤치마크 도구가 없어 정확한 응답 시간을 측정하지 못했다. ~101ms는 중간 개선 버전의 측정값이다.
8. 교훈
이론적 병목 ≠ 실제 병목
| 가설 | 이론 | 실측 |
|---|---|---|
| prefix → edge_ngram | expensive query를 term lookup으로 전환 | 인덱스 크기 증가로 역효과 |
| 17 term → 1 script | 함수 17개 순회 제거 | filter cache로 이미 빠름 |
| _source 필터링 + dis_max 전환 | 쿼리 구조 단순화 + 전송량 감소 | 17% 일관된 개선 |
왜 이론과 실측이 달랐을까?
edge_ngram의 역효과: edge_ngram 필드는 하나의 값에서 여러 개의 prefix 토큰을 생성한다. "래미안파크"라는 5글자 값에서 5개의 토큰이 만들어지고, 이게 540만 건 × 여러 필드에 적용되면 역색인 크기가 상당히 늘어난다. term lookup으로의 전환 이점보다 커진 인덱스로 인한 전반적 성능 저하가 더 컸다.
filter cache의 위력: OpenSearch는 filter 컨텍스트의 쿼리 결과를 bitset으로 캐싱한다. term 필터가 각각 캐싱되어 있으면, 순회 비용은 bitset lookup에 불과하다. script_score는 이 캐시를 활용할 수 없으므로 오히려 이점이 없었다.
실질적 병목은 전송량: 쿼리 실행 시간 자체보다 응답 직렬화 + 네트워크 전송에서 시간을 잡아먹고 있었다. 검색 보조용 필드를 응답에서 제외하는 것만으로도 페이로드가 크게 줄었다.
기술적 교훈
-
이론적으로 "확실한" 개선안을 맹신하지 말 것. 공식 문서의 expensive query 분류가 맞더라도, 실제 데이터와 인덱스 구조에서 병목이 되는지는 측정해봐야 안다.
-
가장 단순한 접근이 가장 효과적일 수 있다. 복잡한 인덱스 구조 변경(edge_ngram 재인덱싱 2시간)보다 불필요한 필드 제거(코드 몇 줄)가 더 나은 결과를 냈다.
-
벤치마크 도구를 먼저 만들어라. Python 스크립트로 벤치마크를 자동화해두니, 각 시도의 효과를 몇 분 만에 정량적으로 확인할 수 있었다. 이게 없었으면 "체감상 비슷한데?" 하고 넘어갔을 것이다.
협업에서의 반성
기술적 교훈 못지않게 크게 느낀 것이 소통의 중요성이다.
1차 배포 이후, 성능 개선에 집중하면서 이런저런 시도를 혼자 진행했다. 이 과정에서 기획팀, QA팀과의 논의가 매우 적었다. 성능을 위해 사전순 정렬을 제거한 부분이나, 전반적인 정렬 순서 변경에 대한 협의와 전파가 제대로 이루어지지 않았다.
기획팀과는 정렬 정책 변경에 대한 합의가 이루어졌지만, 그 내용이 QA팀에 공유되지 않았다. QA팀에서는 기존 정렬이 원래 사양인 줄 알고 변경된 정렬을 버그로 이슈 등록하는 일이 발생했다. 개발자 혼자 기획과 합의했다고 끝이 아니라, 관련된 모든 팀에 변경 사항이 전달되어야 한다는 당연한 사실을 놓쳤다.
기획팀의 정렬 정책 자체도 슬랙, 노션 등 2~3곳에 흩어져 있어 정리하고 협의하는 과정이 힘들었다. 이번 작업을 계기로 기획팀에 요청하여 정렬 정책을 하나의 문서로 통합 관리하도록 정리했다.
기술적으로 아무리 좋은 개선이라도, 팀 전체가 변경 사항을 인지하지 못하면 혼란만 남는다. 이번 경험을 통해 협업과 커뮤니케이션의 중요성을 깊이 반성하게 됐다.
실제 검색 결과
최종 결과는 짐싸 앱에서 직접 확인할 수 있다. ngram 중간 매칭, prefix 매칭, 건물명 + 도로명 통합 검색이 모두 정상 동작한다.
| "늘채빌" 검색 (ngram 중간 매칭) | "노루" 검색 (prefix 매칭) |
|---|---|
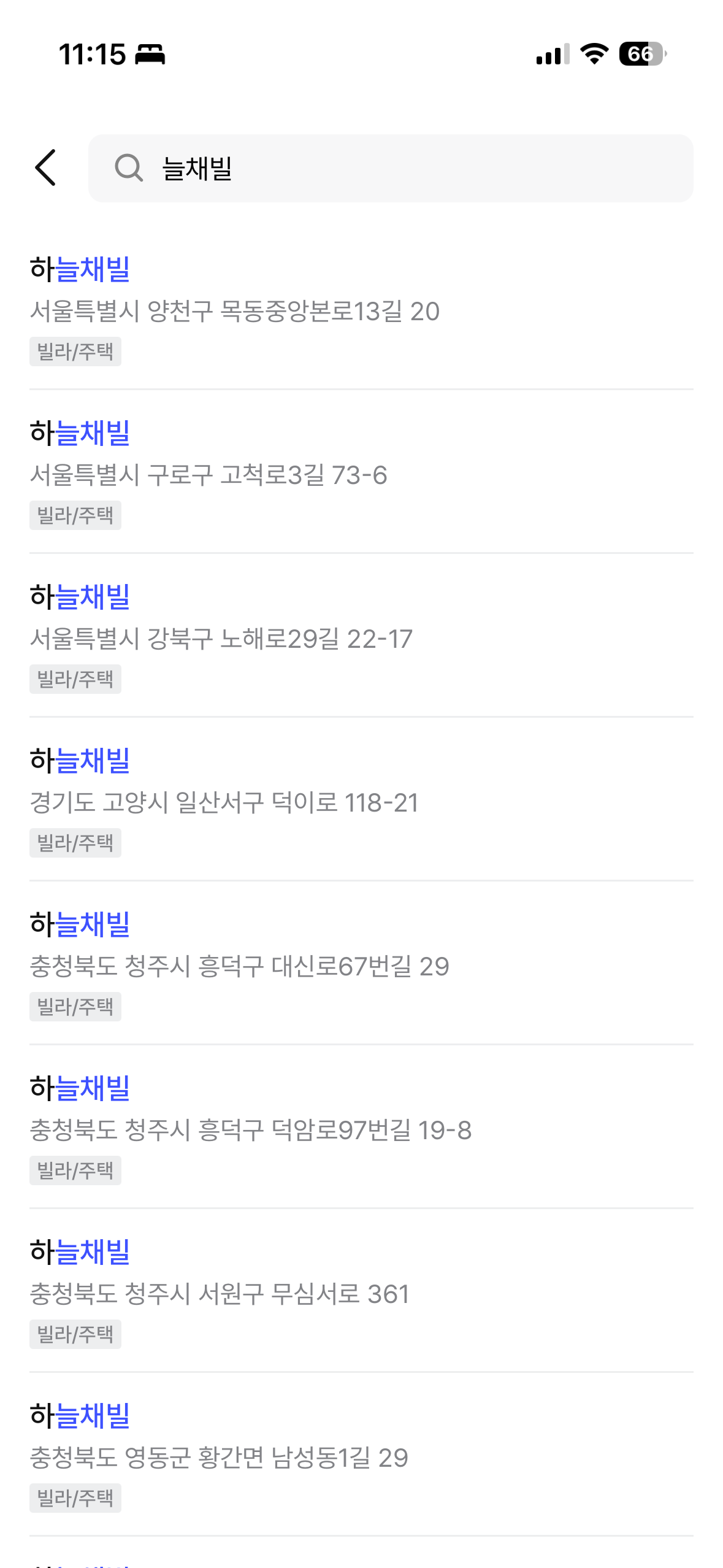 | 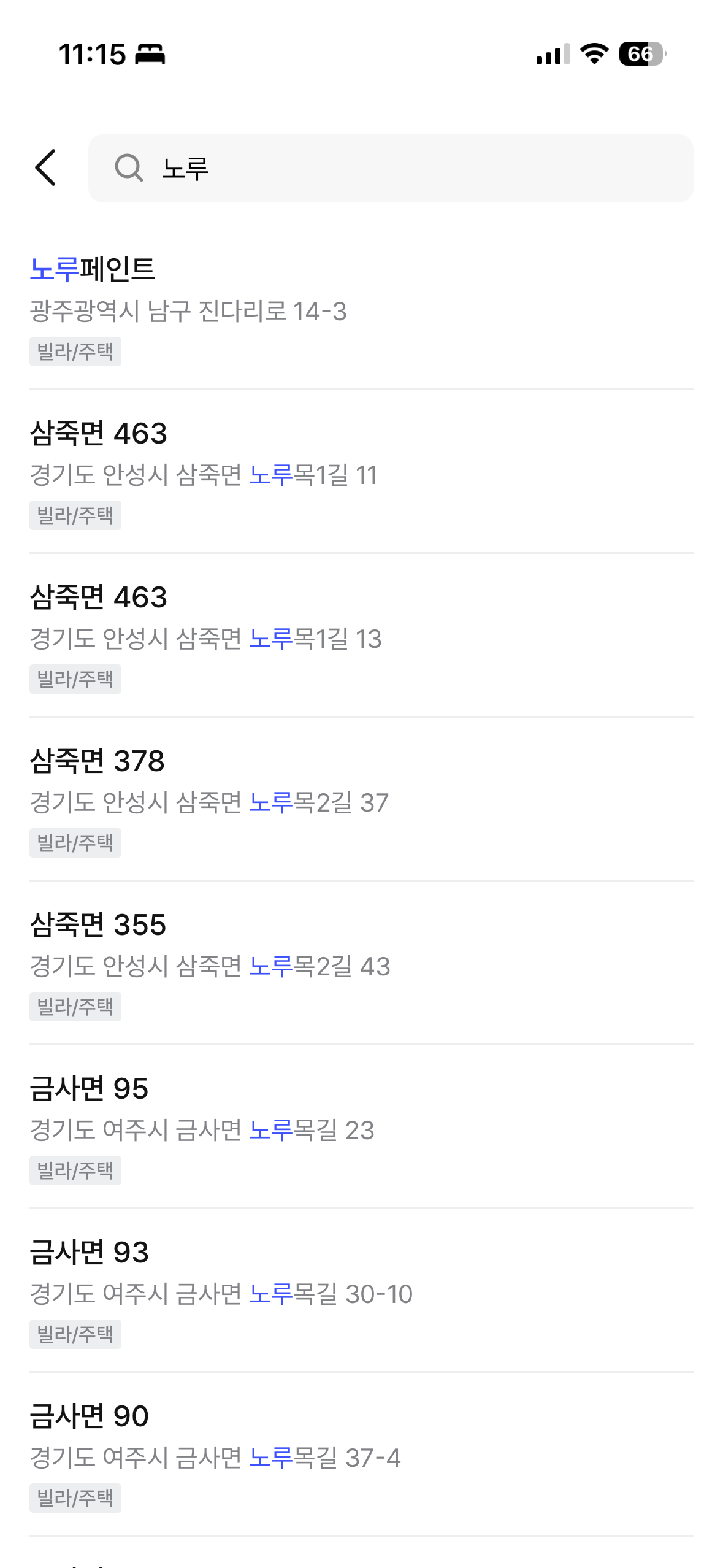 |
| "늘채" 검색 (ngram 중간 매칭) | "테헤란" 검색 (건물명 + 도로명 통합) |
|---|---|
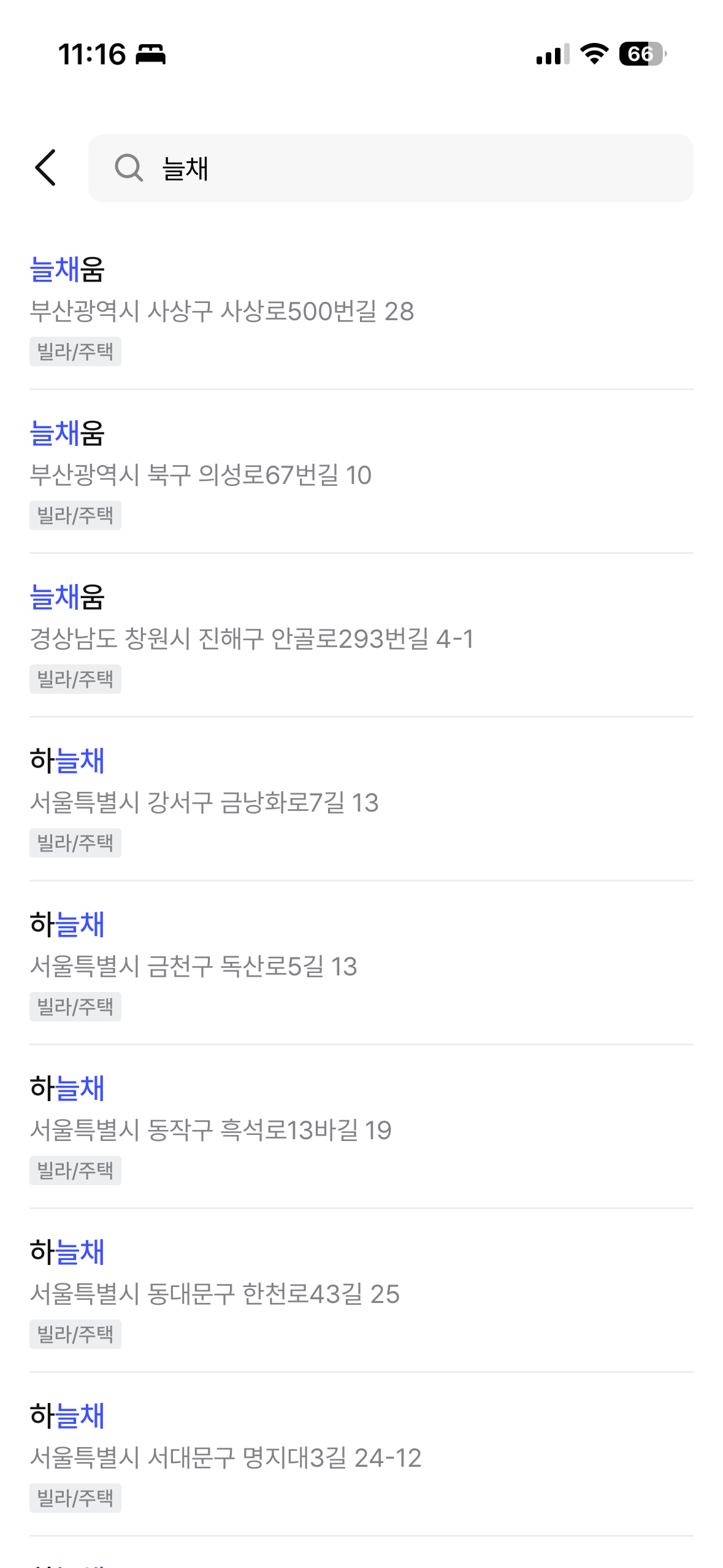 | 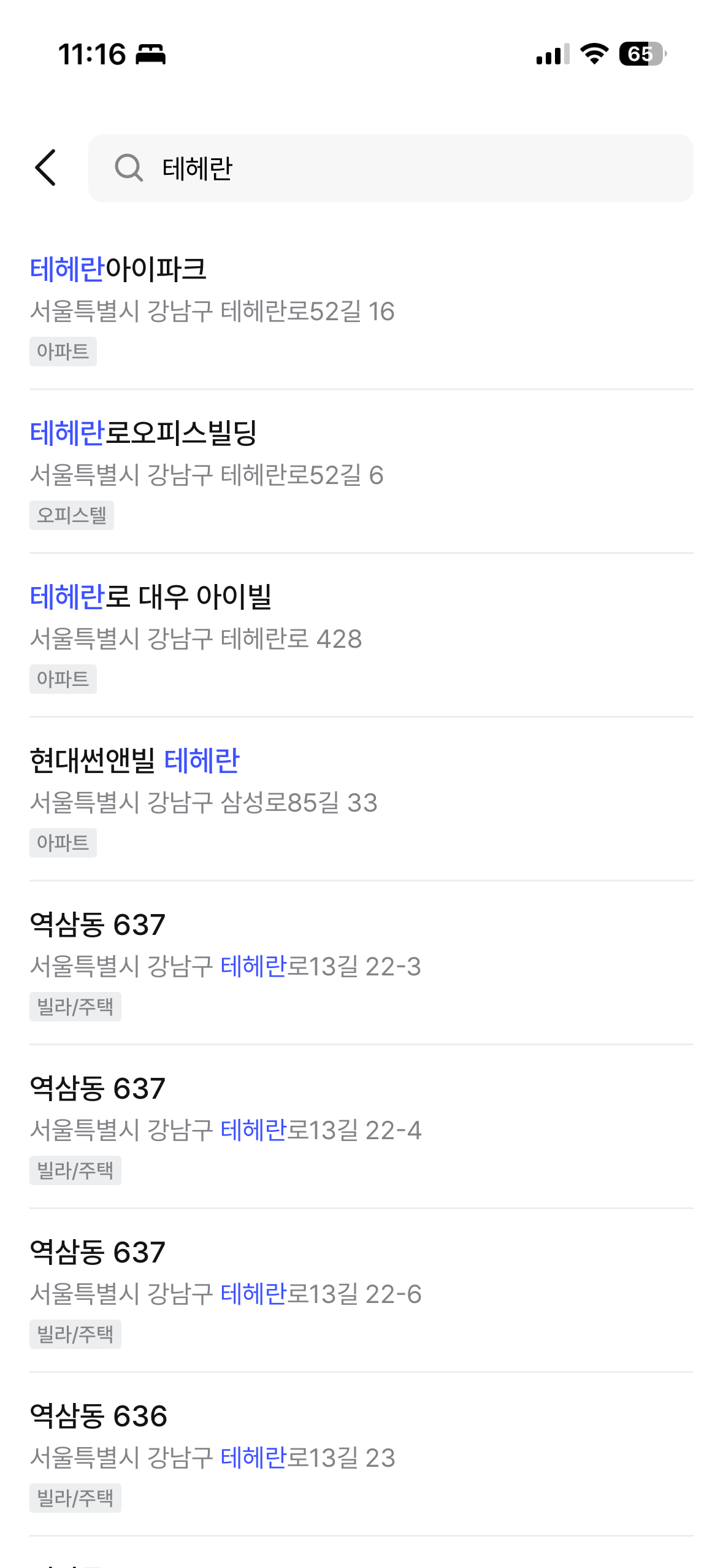 |
짐싸 앱에서 직접 검색해보세요. App Store | Google Play
마무리
83ms는 개선 전보다 나아졌지만, 자동완성의 업계 평균(10~30ms)에는 여전히 훨씬 미치지 못한다. 이게 최선이 아니라는 점을 잘 알고 있다. 캐시 도입, Completion Suggester 전환 등 다음 단계로 나아갈 방법을 시간이 날 때마다 확인하고 있다. AI가 검색 영역에도 본격적으로 도입되고 있는 지금, 업계 수준에 맞추기 위해 더 공부하고 정진할 것이다.
성능 최적화에서 가장 중요한 것은 측정이다. 그리고 측정만큼 중요한 것은 공유다.