Building a Search Engine for 5.4 Million Real Estate Records: From OpenSearch Adoption to Performance Optimization
Contents
- 1. Background: Limitations of the Existing Search
- Existing Architecture
- Limitations
- 2. Adopting OpenSearch
- Technology Selection
- Establishing the Search Policy
- Designing Search Categories
- 3. Index Design
- Field Structure
- 4. First Deployment: Just Make It Work (2026.03)
- First Deployment Query Structure
- Limitations of the First Deployment
- 5. Intermediate Improvements: ngram and Query Structure Changes
- Introducing ngram
- Removing Script Sort and Sorting Compromises
- 6. Benchmark-Driven Performance Optimization
- Benchmark Environment
- Attempt 1: Reducing 17 Functions to 1 with scriptscore
- Attempt 2: Replacing prefix Queries with edgengram
- Attempt 3: source Filtering + Complete Query Structure Overhaul
- 7. Second Deployment: Final Results (2026.04)
- Three-Stage Evolution Summary
- 8. Lessons Learned
- Theoretical Bottleneck ≠ Actual Bottleneck
- Why Did Theory and Measurement Diverge?
- Technical Lessons
- Reflections on Collaboration
- Live Search Results
- Closing
To overcome the limitations of DB + public API-based search, we adopted OpenSearch and designed, built, and optimized an autocomplete search engine for 5.4 million real estate records. Here's the full story.
1. Background: Limitations of the Existing Search
In October 2025, while organizing nationwide residential property information, we needed a search feature that allowed customers to quickly find their desired homes. At the time, no one on the team had experience with Elasticsearch, and with a tight launch deadline, there was no time to learn. So we went with whatever worked.
Existing Architecture
- Building name search: LIKE queries against the DB
- Address search: juso.go.kr public API calls
- Routing logic: regex to determine whether the input was a building name or an address
Limitations
Three problems accumulated.
Regex routing errors: When a road name fell outside the regex patterns, keywords meant for juso.go.kr would be sent to the DB, or building names would be routed to the public API. This happened intermittently but persistently.
No sort control: juso.go.kr responses came in whatever order the API returned. There was no way to apply the region-based priorities or building name length sorting that the product team wanted.
Performance ceiling: No amount of indexing could make LIKE queries over 5.4 million records fast enough. This was especially true for autocomplete patterns where requests fire on every keystroke. Keywords like "apartment", "house", or "villa" that match millions of records nationwide made response times even worse.
2. Adopting OpenSearch
Technology Selection
After internal discussion, our team lead chose AWS OpenSearch over Elasticsearch. The reasons:
- Minimal operational overhead: AWS handles cluster infrastructure management and security patches, so a small team doesn't need to spend time on search engine infrastructure.
- Elasticsearch compatible: As a fork of Elasticsearch 7.10, it leverages the existing ES ecosystem's knowledge and libraries.
- No license risk: Elastic changed the license to SSPL starting from 7.11, but OpenSearch maintains Apache 2.0, so there are no restrictions for commercial services.
- nori Korean morphological analyzer support: The nori plugin for Korean tokenization comes built-in, requiring no separate installation.
Our team lead had already created the OpenSearch cluster and set up the index by mapping building data from our company DB 1:1. No tuning or search queries — just the bare skeleton.
I took over from there to develop the search engine full-time. The priorities were clear:
- Handle building name + road name search in a single service without routing — eliminate the regex routing structure and solve it with a single OpenSearch query
- Guarantee the sort order the product team intended — implement custom sorting logic based on region priority, building name length, etc.
- Fast response times — achieve autocomplete-level response speed even for keywords like "apartment" or "house" that match millions of records
Establishing the Search Policy
The search ranking order the product team wanted was:
1. Exact keyword match takes highest priority
2. Keywords matching the beginning of the building name (prefix) come next
3. Shorter building names first
4. Building names in lexicographic order
5. In the specified region order (Seoul > Gyeonggi > Incheon > ...)Designing Search Categories
| Category | Example |
|---|---|
| Exact complex/building name match | "Cheongundong Lime County" |
| Complex/building name prefix | "Cheongundong", "Lime" |
| Keywords with spaces | "Lime County Cheongundong" (handles reordering) |
| Exact road name match | "Sagajeong-ro", "Sagajeong-ro 232" |
| Region + district + keyword combination | "Seoul Dongdaemun-gu Sagajeong-ro 232" |
3. Index Design
We adopted a dual-field strategy of Text (morphological analysis) vs Keyword (exact match):
name → text (morphological analysis, for match queries)
name.keyword → keyword (exact match, for prefix queries)
name_normalized → keyword (normalized, handles spacing variations)Why the normalized field: In "Seoul Gangnam-gu Teheran-ro 212", the presence or absence of a space between "Teheran-ro" and "212" could change search results. We created a separate normalized field with all spaces and special characters removed to absorb such edge cases.
Field Structure
| Field Type | Type | Purpose |
|---|---|---|
| Building name | text + keyword | Morphological search + exact match |
| Building name normalized | keyword | Spacing variation handling |
| Road name normalized | keyword | Road name prefix matching |
| Lot number normalized | keyword | Lot number prefix matching |
| Combined search text | text | Unified search across all fields |
| Region priority | integer | Product team's region order stored as integer |
4. First Deployment: Just Make It Work (2026.03)
At that point, I was encountering OpenSearch for the first time. Starting development without sufficient study meant the query structure ended up quite heavy.
First Deployment Query Structure
Text search was built with function_score + bool(should) with 7 clauses: building name morphological matching, combined text matching, and normalized prefix matching for building name/road name/lot number. Six functions were added to function_score to assign weights in order of building name exact match, normalized match, and prefix match.
The problem was sorting. To guarantee the sort order the product team wanted, I used an 8-stage Painless script sort:
1. Building name existence
2. Building name - keyword match
3. Match type (exact > prefix)
4. Building name length order
5. Building name lexicographic order
6. Region priority
7. Road name prefix match (when no building name)
8. Road name lexicographic orderThis meant executing 8 Painless scripts on every matching document for every request. The more documents a keyword matched, the greater the performance burden.
Limitations of the First Deployment
Script sort performance overhead: With 8-stage scripts running per document, keywords matching many documents were slow.
No partial matching: Without ngram, searching "Haneulchae Building" with "neulchae" returned no results.
No _source filtering: Responses were returning all fields from the index.
Still, the original problems we set out to solve — regex routing errors, no sort control, LIKE query performance — were resolved. Performance was better than DB + juso.go.kr queries, and the intermittent routing errors were gone. With the first milestone achieved, we deployed.
5. Intermediate Improvements: ngram and Query Structure Changes
After the first deployment, I began studying OpenSearch in earnest and incrementally improved the query structure.
Introducing ngram
To solve the partial matching problem, I added an ngram analyzer to the index. With min_gram=2, max_gram=3, "Haneulchae Building" gets tokenized into "Haneul", "neulchae", "chaeBuild", "Building", etc., making search by "neulchae" possible.
Removing Script Sort and Sorting Compromises
I removed the 8-stage Painless script sort and switched to a structure where scoring itself reflects the sort order. Region priority was implemented through function_score's filter + weight structure, and building name length through linear decay.
However, in this process, the product team's sorting policy wasn't fully implemented. There were compromises like removing lexicographic sorting for performance, and some details of the sort priority order differed from the first deployment. I'll revisit this later.
The query structure at this point:
function_score
├── query: bool
│ ├── filter: building type filter
│ └── should (minimum_should_match=1):
│ ├── L1: Building name exact match — term
│ ├── L2: Building name prefix — prefix
│ ├── L2.5: Building name ngram — match(ngram)
│ ├── L3: Morphological match — match(nori)
│ ├── L4a: Road name prefix — prefix
│ ├── L4b: Lot number prefix — prefix
│ └── L4c: Address ngram — match(ngram)
└── functions:
├── 17 region priority filters (region bonus)
└── 1 linear decay (building name length bonus)The 6 function_score functions from the first deployment grew to 18 (17 region filters + 1 decay), but the 8-stage script sort was eliminated. The partial matching problem was also solved. However, response times were still in the 100-150ms range. The industry expectation for autocomplete is typically 10-30ms.
6. Benchmark-Driven Performance Optimization
We ran benchmarks against the intermediate improvement version.
Benchmark Environment
- AWS OpenSearch dev environment, 5.4 million real records
- Single request measurement (no concurrent requests)
- Warm cache state (same queries run before benchmark for cache warming)
- 41 keywords x 10 repetitions, 7 categories
- Measurements are averages of 10 runs
- Automated with a Python benchmark script
I analyzed the intermediate version's query structure and formed three performance bottleneck hypotheses:
| Bottleneck | Hypothesis |
|---|---|
| A. 6 prefix queries | Prefix on high-cardinality keyword fields could be expensive |
| B. 18 function_score functions | All 18 functions traverse every document |
| C. ngram index size | min_gram=2, max_gram=3 → token count explosion |
Attempt 1: Reducing 17 Functions to 1 with script_score
Starting with the easiest-looking option. I consolidated 17 region priority term filters into a single Painless script.
// Before: 17 filters
{ filter: { term: { rank: 1 } }, weight: ... }
{ filter: { term: { rank: 2 } }, weight: ... }
// ... ×17
// After: 1 script
{ script_score: { script: "score calculation formula based on rank value" } }Result: ±10ms. Within network jitter range. No effect.
OpenSearch's filter cache was caching term filter results as bitsets, making traversal of all 17 extremely cheap. This was consistent with Elastic's official documentation classifying script_score as an "expensive function."
Attempt 2: Replacing prefix Queries with edge_ngram
This was theoretically the most certain improvement.
The prefix query on keyword fields is classified as an expensive query even in the official documentation. With 5.4 million records, the number of unique terms is substantial, so I hypothesized this could be the bottleneck. An edge_ngram analyzer generates prefix tokens at index time, converting them to regular term lookups.
I added an edge_ngram tokenizer + 6 new fields to the index and re-indexed 5.4 million records (~2 hours).
Results:
| Category | prefix (ms) | edge_ngram (ms) | Difference |
|---|---|---|---|
| Building name exact | 107.5 | 108.1 | +0.6 |
| Building name short | 108.4 | 130.7 | +22.3 |
| Road name | 99.4 | 109.0 | +9.6 |
| 1-char | 112.3 | 118.8 | +6.5 |
| Overall average | ~101 | ~110 | +9ms (actually slower) |
Counterproductive. Adding 6 edge_ngram fields increased the index size, and all queries running against the larger index became slower overall.
At the 5.4-million-record scale, prefix queries were not the actual bottleneck.
Attempt 3: _source Filtering + Complete Query Structure Overhaul
Shifting direction from theoretical optimization, I focused on reducing actual payload size + simplifying query structure.
Changes:
- Complete query structure overhaul: Switched from
function_score+bool(should)→dis_max+constant_score5-tier structure. Removed the 17 region filters from function_score and simplified sorting to_score desc → building name length asc → region priority asc. - _source filtering: Only return the 7 fields actually used in the response. Previously, the full source fields from the index were being returned, including normalized and combined text fields used only for search scoring, resulting in unnecessarily large payloads.
- 1-character search optimization: For single-character inputs, only exact match and prefix matching execute, skipping unnecessary ngram/morphological matching.
Results (compared to intermediate version):
| Category | Intermediate (ms) | Final (ms) | Improvement |
|---|---|---|---|
| Building name exact | 107.5 | 94.9 | -12% |
| Building name prefix | 98.2 | 88.5 | -10% |
| Building name short | 108.4 | 89.2 | -18% |
| Road name | 99.4 | 85.7 | -14% |
| Lot number | 99.7 | 89.7 | -10% |
| 1-char | 112.3 | 67.5 | -40% |
| Overall average | ~101 | ~83 | -17% |
Consistent improvement across all categories. The 1-character search improved 40% thanks to significantly fewer query clauses executing.
7. Second Deployment: Final Results (2026.04)
Three-Stage Evolution Summary
[1st Deployment] function_score + bool(should) 7 clauses + 8-stage script sort
├── function_score: 6 functions (weight-based)
├── sort: 8-stage Painless script
├── ngram: none
└── _source: full response
[Intermediate] function_score + bool(should) 7 clauses
├── function_score: 18 functions (17 region filters + 1 decay)
├── sort: _score desc (script sort removed)
├── ngram: building name + address
└── _source: full response
[2nd Deployment] dis_max + constant_score 5-tier
├── T1: Building name exact match — term
├── T2: Building name prefix — prefix
├── T3: Building name ngram partial — match(ngram)
├── T4: Morphological match — match(nori)
├── T5: Address prefix + ngram — prefix + match(ngram)
├── sort: _score desc → building name length asc → region priority asc
├── 1-char search: only T1, T2 execute
└── _source: only 7 fields returned| Item | 1st Deployment | Intermediate | 2nd Deployment |
|---|---|---|---|
| Query structure | function_score + 7 should clauses | function_score + 7 should clauses | dis_max + constant_score 5-tier |
| Sorting | 8-stage Painless script sort | _score desc | _score desc + 2 fields |
| function_score functions | 6 | 18 (17+1) | 0 |
| ngram | None | Building name + address | Building name + address |
| Partial matching | Not supported | Supported | Supported |
| _source filtering | None | None | 7 fields only |
| Avg response time | Not measured | ~101ms | ~83ms (17% down) |
No benchmark tools existed at the time of the first deployment, so exact response times weren't measured. ~101ms is from the intermediate version.
8. Lessons Learned
Theoretical Bottleneck ≠ Actual Bottleneck
| Hypothesis | Theory | Measurement |
|---|---|---|
| prefix → edge_ngram | Convert expensive query to term lookup | Index size increase caused worse performance |
| 17 term → 1 script | Eliminate traversal of 17 functions | Filter cache made it already fast |
| _source filtering + dis_max overhaul | Simplify query structure + reduce payload | 17% consistent improvement |
Why Did Theory and Measurement Diverge?
edge_ngram's countereffect: edge_ngram fields generate multiple prefix tokens from a single value. A 5-character value like "Raemian Park" produces 5 tokens, and when applied across 5.4 million records x multiple fields, the inverted index grows substantially. The cost of the larger index degrading overall performance outweighed the benefit of switching to term lookups.
The power of filter cache: OpenSearch caches filter context query results as bitsets. When term filters are individually cached, the traversal cost is nothing more than a bitset lookup. script_score cannot leverage this cache, so there was actually no advantage.
The real bottleneck was payload size: More time was spent on response serialization + network transfer than on query execution itself. Simply excluding search-auxiliary fields from the response significantly reduced the payload.
Technical Lessons
-
Don't blindly trust "certain" theoretical improvements. Even if the official documentation's expensive query classification is correct, whether it's actually a bottleneck with your real data and index structure can only be determined by measuring.
-
The simplest approach can be the most effective. Removing unnecessary fields (a few lines of code) produced better results than complex index structure changes (2-hour edge_ngram re-indexing).
-
Build the benchmark tool first. With a Python script automating benchmarks, I could quantitatively verify each attempt's effect in minutes. Without it, I would have just thought "feels about the same" and moved on.
Reflections on Collaboration
Alongside technical lessons, what I felt most strongly was the importance of communication.
After the first deployment, I pushed forward with various experiments on my own while focusing on performance improvement. During this process, discussions with the product team and QA team were severely lacking. Compromises like removing lexicographic sorting for performance, and changes to the overall sort order, weren't properly discussed and communicated.
While the product team and I reached agreement on the sorting policy changes, that information wasn't shared with QA. The QA team, assuming the original sorting was the intended specification, filed the changed sorting as a bug. I overlooked the obvious fact that reaching agreement with the product team alone isn't enough — changes need to be communicated to all related teams.
The product team's sorting policy itself was scattered across 2-3 places like Slack and Notion, making it difficult to consolidate and discuss. Using this project as an opportunity, I requested the product team to unify the sorting policy into a single document.
No matter how good a technical improvement is, if the entire team isn't aware of the changes, only confusion remains. This experience deeply reminded me of the importance of collaboration and communication.
Live Search Results
You can see the final results in the Zimssa app. ngram partial matching, prefix matching, and combined building name + road name search all work as intended.
| "늘채빌" search (ngram partial match) | "노루" search (prefix match) |
|---|---|
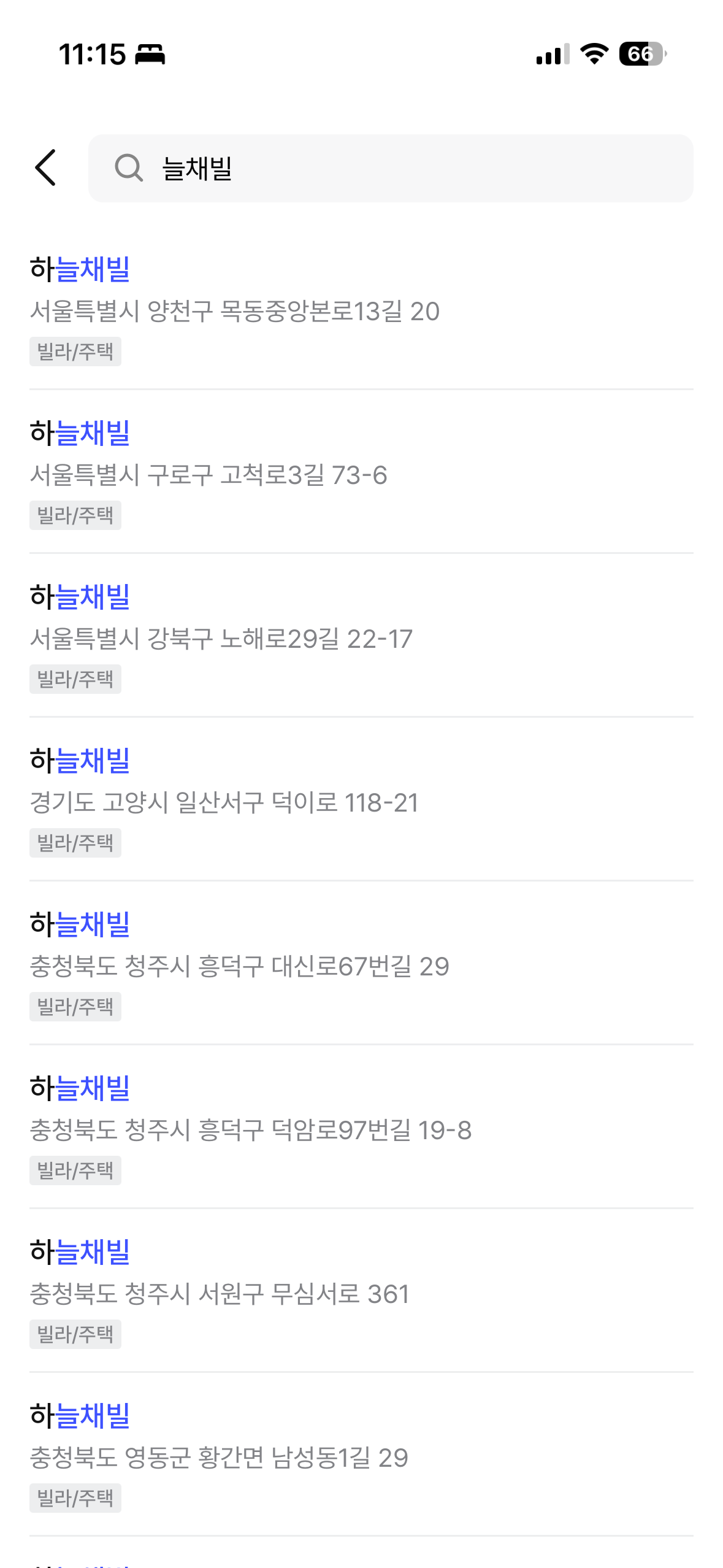 | 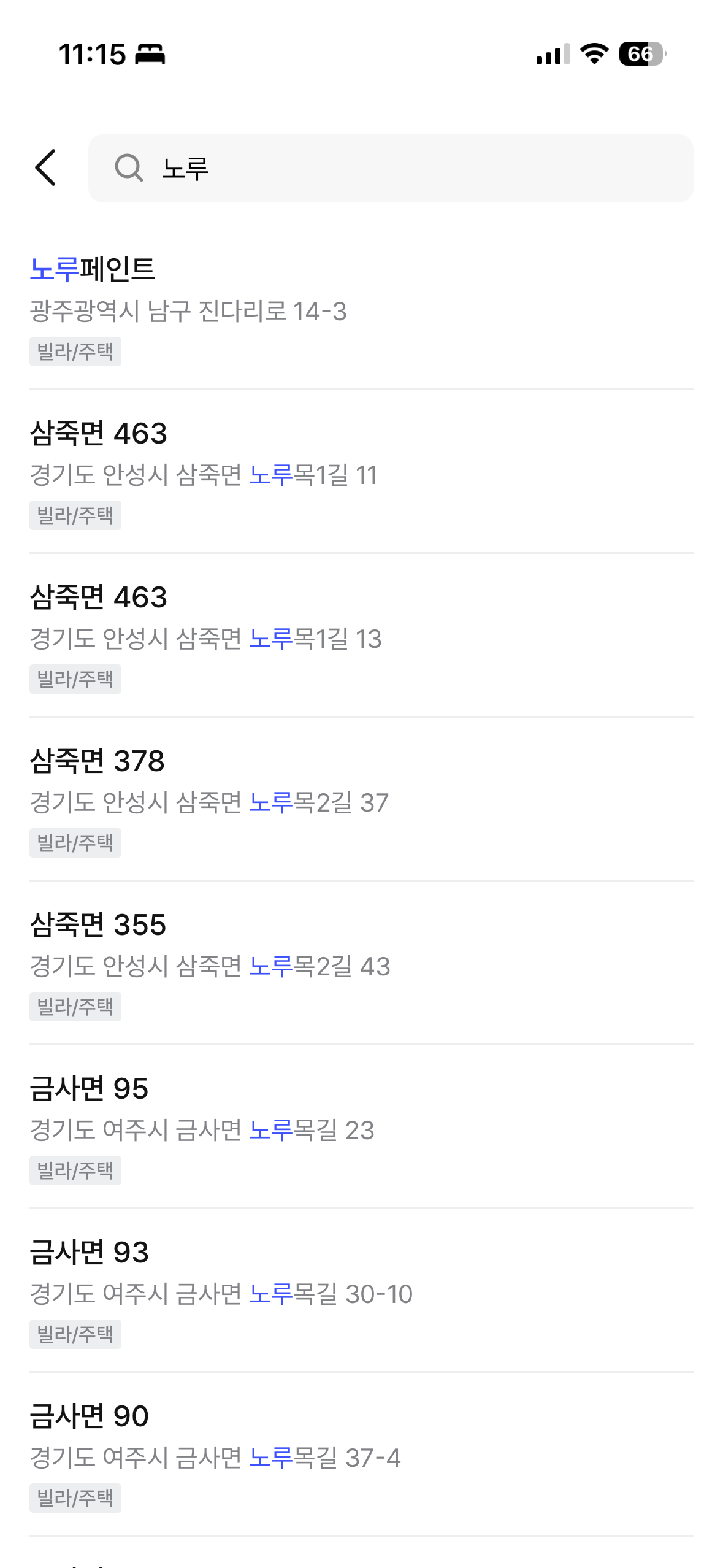 |
| "늘채" search (ngram partial match) | "테헤란" search (building + road name) |
|---|---|
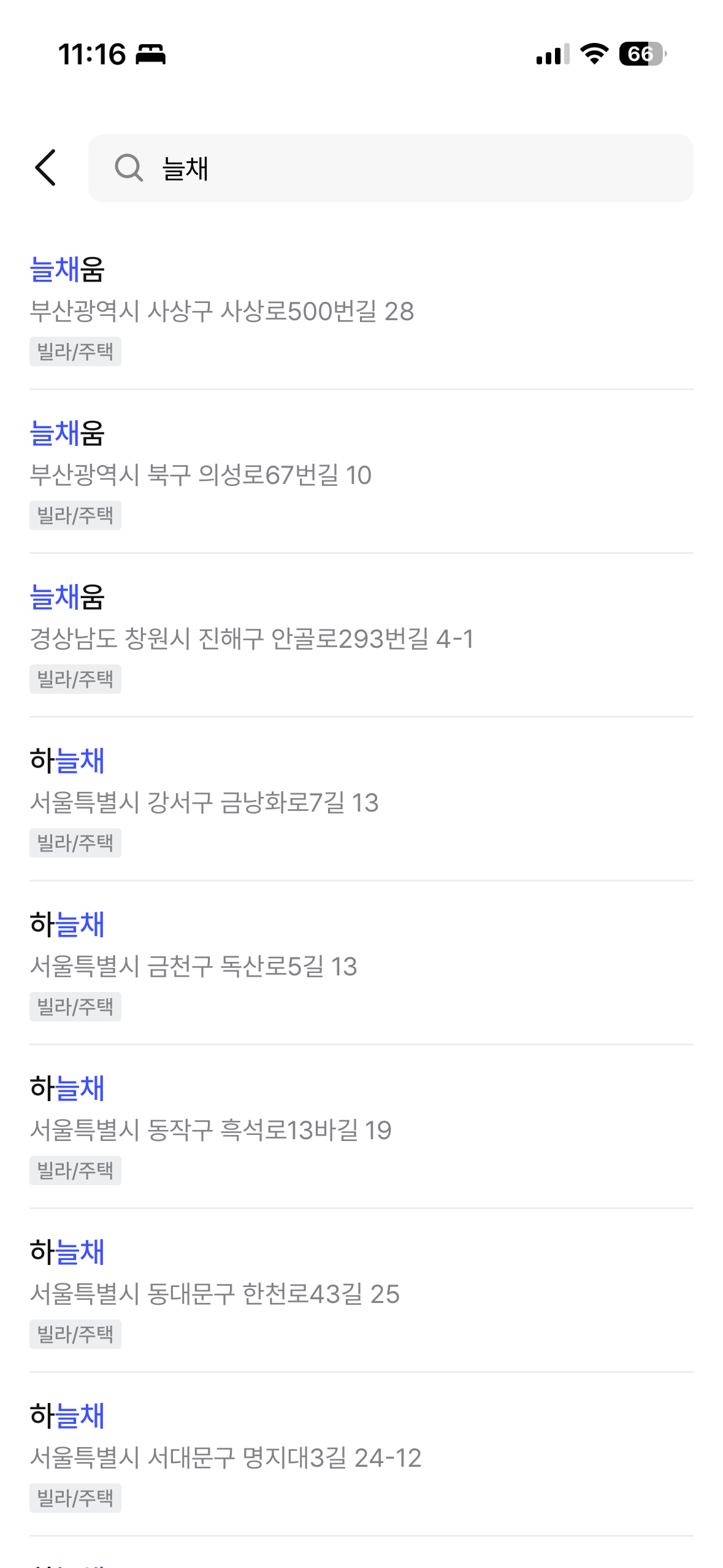 | 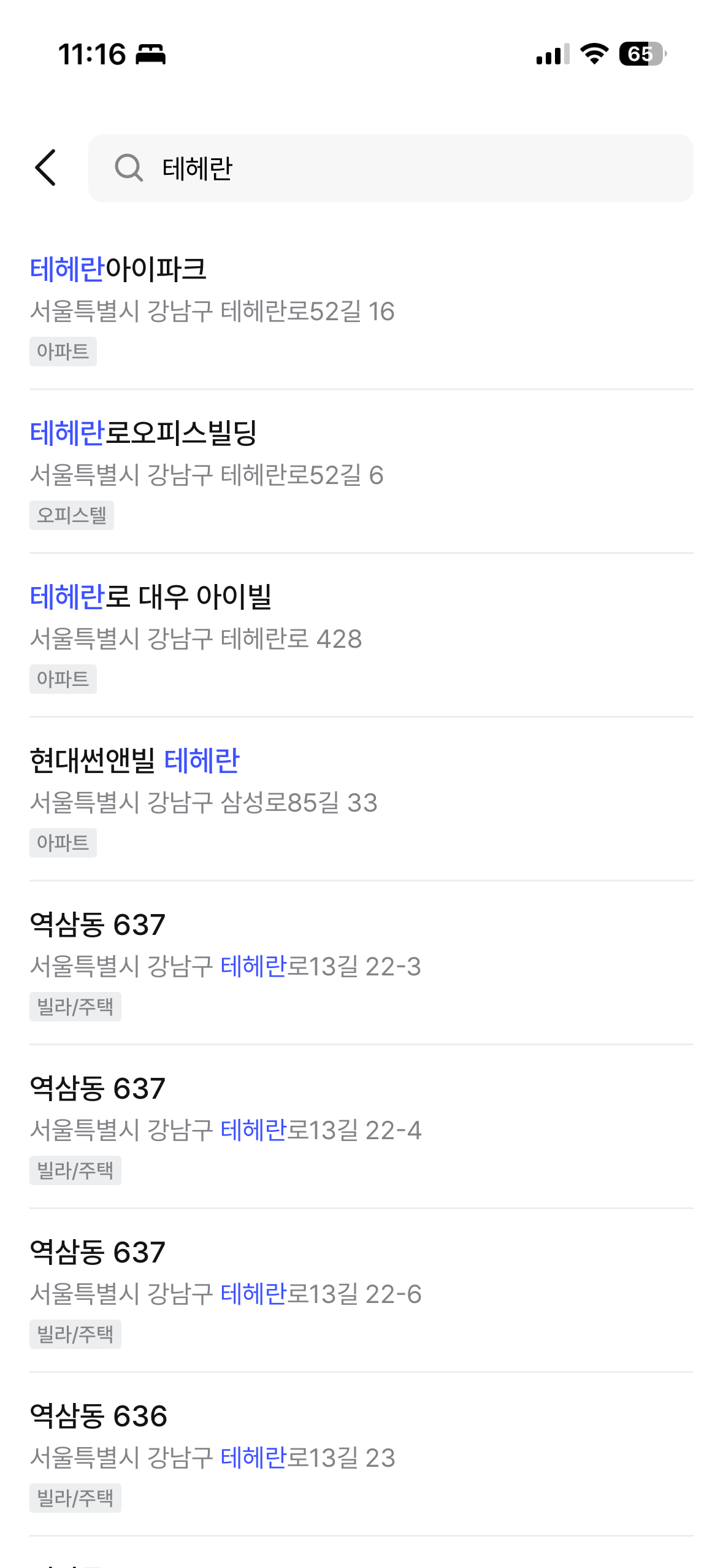 |
Try searching in the Zimssa app yourself. App Store | Google Play
Closing
83ms is better than before, but still far from the industry average for autocomplete (10-30ms). I'm well aware this isn't the best we can do. I keep exploring next steps like caching and switching to Completion Suggester whenever I find the time. With AI now making serious inroads into the search domain, I'll continue studying and pushing to reach industry standards.
The most important thing in performance optimization is measurement. And what's just as important as measurement is sharing.