540万件の不動産検索エンジン構築記:OpenSearch導入からパフォーマンス最適化まで
目次
- 1. 背景:既存検索の限界
- 既存の構成
- 限界
- 2. OpenSearch導入
- 技術選択
- 検索ポリシーの策定
- 検索カテゴリの設計
- 3. インデックス設計
- フィールド構造
- 4. 第1次デプロイ:まず動くように(2026.03)
- 第1次デプロイのクエリ構造
- 第1次デプロイの限界
- 5. 中間改善:ngram導入とクエリ構造変更
- ngram導入
- script sort削除とソートの妥協
- 6. ベンチマーク基盤パフォーマンス最適化
- ベンチマーク環境
- 試行1:scriptscoreで関数17個を1個に削減
- 試行2:edgengramでprefixクエリを置換
- 試行3:sourceフィルタリング + クエリ構造全面転換
- 7. 第2次デプロイ:最終結果(2026.04)
- 3段階の変遷まとめ
- 8. 教訓
- 理論的ボトルネック ≠ 実際のボトルネック
- なぜ理論と実測が異なったのか?
- 技術的教訓
- 協業における反省
- 実際の検索結果
- まとめ
DB + 公共API基盤の検索の限界を克服するためにOpenSearchを導入し、540万件の不動産データに対するオートコンプリート検索エンジンを設計・構築・最適化した全過程を共有する。
1. 背景:既存検索の限界
2025年10月、全国の住居情報を整理する中で、顧客が望む物件を素早く探索できる検索機能が必要になった。当時チーム内にElasticsearchを扱った経験者がおらず、リリースを急ぐ状況で学習する時間もなかった。そこで、まず動く方法で実装した。
既存の構成
- 建物名検索:DBでLIKE検索
- 住所検索:juso.go.kr 公共APIコール
- 分岐処理:regexで入力値が建物名か住所かを判断
限界
3つの問題が蓄積された。
regex分岐エラー:regexを外れる道路名が入力されると、juso.go.krに送るべきキーワードがDBに渡されたり、逆に建物名が公共APIに流れるケースが間欠的に発生していた。
ソート制御不可:juso.go.krのレスポンスはAPIが返す順序そのままだった。企画チームが望む地域優先順位や建物名の長さ基準のソートを適用する方法がなかった。
パフォーマンスの限界:540万件に対するLIKE検索はインデックスをどれだけ適切に設定しても限界があった。オートコンプリートのようにタイピングの度にリクエストが発生するパターンではなおさらだった。特に「アパート」「住宅」「ビラ」のように全国的に広範に使われるキーワードは数百万件がマッチし、レスポンス時間がさらに長くなった。
2. OpenSearch導入
技術選択
チーム内の議論の結果、チームリーダーがElasticsearchではなくAWS OpenSearchを選択した。理由をいくつかまとめると:
- 管理負担の最小化:クラスタインフラの運用とセキュリティパッチをAWSが担当するため、少人数チームが検索エンジンインフラに時間を割く必要がない。
- Elasticsearchとの互換性:Elasticsearch 7.10ベースのForkであり、既存のESエコシステムの知見やライブラリをそのまま活用できる。
- ライセンスリスクなし:Elasticが7.11からSSPLにライセンスを変更したが、OpenSearchはApache 2.0を維持しているため、商用サービスでの制約がない。
- nori韓国語形態素解析器対応:韓国語トークン化のためのnoriプラグインが標準搭載されており、別途インストール不要。
チームリーダーが先にOpenSearchクラスタを作成し、会社DBの建物データを1:1マッピングしてインデックスに投入した状態までセットアップしてくれた。チューニングや検索クエリはない、骨組みだけの状態だった。
これを引き継いで検索エンジンを専任で開発することになった。優先順位は明確だった。
- 建物名 + 道路名検索を分岐なしで一つのサービスで処理 — 既存のregex分岐構造を廃止し、OpenSearch単一クエリで解決
- 企画チームが意図するソート順序を保証 — 地域優先順位、建物名の長さなどのカスタムソートロジック実装
- 高速レスポンス — 「アパート」「住宅」のように数百万件がマッチするキーワードでもオートコンプリートレベルのレスポンス速度を確保
検索ポリシーの策定
企画チームが求めた検索ソート順位は以下の通りだった:
1. キーワード100%完全一致が最優先
2. キーワードが建物名の先頭にある(prefix)検索語が次
3. 建物名が短い順
4. 建物名の辞書順
5. 指定した地域順(ソウル > 京畿 > 仁川 > ...)検索カテゴリの設計
| カテゴリ | 例 |
|---|---|
| 団地名/建物名完全一致 | 「清雲洞ライムカウンティ」 |
| 団地名/建物名prefix | 「清雲洞」「ライム」 |
| スペース含むキーワード | 「ライムカウンティ 清雲洞」(順序変更対応) |
| 道路名正確一致 | 「四佳亭路」「四佳亭路 232」 |
| 地域+市郡区+キーワード組合 | 「ソウル 東大門区 四佳亭路 232」 |
3. インデックス設計
Text(形態素解析)vs Keyword(完全一致)の二重フィールド戦略を採用した:
name → text(形態素解析、match検索用)
name.keyword → keyword(完全一致、prefix検索用)
name_normalized → keyword(正規化、スペース例外対応)normalizedフィールド導入の理由:「ソウル特別市 江南区 テヘラン路 212」で「テヘラン路」と「212」の間のスペースの有無によって検索結果が変わる可能性がある。すべてのスペース・特殊文字を除去したnormalizedフィールドを別途用意して、このような例外を吸収した。
フィールド構造
| フィールドタイプ | 型 | 用途 |
|---|---|---|
| 建物名 | text + keyword | 形態素検索 + 完全一致 |
| 建物名正規化 | keyword | スペース例外対応 |
| 道路名正規化 | keyword | 道路名prefixマッチング |
| 地番正規化 | keyword | 地番prefixマッチング |
| 統合検索テキスト | text | 全フィールドを合わせた統合検索 |
| 地域優先順位 | integer | 企画チームが定義した地域順序を整数で保存 |
4. 第1次デプロイ:まず動くように(2026.03)
当時、OpenSearchに初めて触れるレベルだった。勉強不足のまま開発を始めたため、クエリ構造がかなり重くなった。
第1次デプロイのクエリ構造
テキスト検索はfunction_score + bool(should) 7節で構成した。建物名の形態素マッチング、統合テキストマッチング、建物名/道路名/地番の正規化prefixマッチングなどだ。function_scoreに6つの関数を追加して、建物名完全一致、正規化一致、prefix一致の順で重みを付与した。
問題はソートだった。企画チームが望むソート順序を保証するために、8段階Painless script sortを使用した:
1. 建物名の存在有無
2. 建物名-キーワードマッチング有無
3. マッチタイプ(完全一致 > prefix)
4. 建物名の長さ順
5. 建物名の辞書順
6. 地域優先順位
7. 道路名prefixマッチ(建物名がない場合)
8. 道路名の辞書順毎リクエストで全マッチングドキュメントに対して8つのPainlessスクリプトを実行する構造だった。ドキュメント数の多いキーワードほどパフォーマンス負担が大きかった。
第1次デプロイの限界
script sortのパフォーマンス負担:8段階スクリプトがドキュメントごとに実行されるため、マッチングドキュメントの多いキーワードではレスポンスが遅かった。
中間マッチング未対応:ngramがなかったため、「ハヌルチェビルディング」を「ヌルチェ」で検索しても結果が出なかった。
_sourceフィルタリングなし:レスポンスでインデックスの全フィールドを返していた。
それでも、元々解決しようとしていた問題 — regex分岐エラー、ソート制御不可、LIKE検索のパフォーマンス — は解消された状態だった。DBクエリ + juso.go.krクエリに比べて改善されたパフォーマンスを保証し、間欠的な分岐エラーも消えた。第1目標を達成したとみなしてデプロイを実行した。
5. 中間改善:ngram導入とクエリ構造変更
第1次デプロイ後、OpenSearchを本格的に勉強しながら、クエリ構造を段階的に改善していった。
ngram導入
中間マッチング問題を解決するためにngramアナライザーをインデックスに追加した。min_gram=2, max_gram=3に設定すると「ハヌルチェビルディング」が「ハヌル」「ヌルチェ」「チェビル」「ビルディ」などのトークンに分解され、「ヌルチェ」でも検索可能になる。
script sort削除とソートの妥協
8段階Painless script sortを削除し、スコアリング自体でソートを反映する構造に転換した。地域優先順位はfunction_scoreのfilter + weight構造で、建物名の長さはlinear decayで反映した。
ただし、この過程で**企画チームのソートポリシーを完全に実装することはできなかった。**パフォーマンスのために辞書順ソートを削除するなどの妥協があり、ソート順序の細部優先順位も第1次デプロイと異なる部分があった。この点については後で再度触れる。
この時点のクエリ構造は以下の通り:
function_score
├── query: bool
│ ├── filter: 建物タイプフィルタ
│ └── should (minimum_should_match=1):
│ ├── L1: 建物名完全一致 — term
│ ├── L2: 建物名prefix — prefix
│ ├── L2.5: 建物名ngram — match(ngram)
│ ├── L3: 形態素マッチング — match(nori)
│ ├── L4a: 道路名prefix — prefix
│ ├── L4b: 地番prefix — prefix
│ └── L4c: 住所ngram — match(ngram)
└── functions:
├── 17個の地域優先順位フィルタ(地域加算点)
└── 1個のlinear decay(建物名長さ加算点)第1次デプロイの6つのfunction_score関数が18個(17地域フィルタ + 1 decay)に増えた代わりに、8段階script sortがなくなった。中間マッチング問題も解決された。しかし、レスポンス時間は依然として100〜150ms水準だった。業界ではオートコンプリートに通常10〜30msを期待する。
6. ベンチマーク基盤パフォーマンス最適化
上記の中間改善バージョンを基準にベンチマークを実行した。
ベンチマーク環境
- AWS OpenSearch dev環境、540万件の実データ
- 単一リクエスト基準の測定(同時リクエストなし)
- ウォームキャッシュ状態(ベンチマーク前に同一クエリでキャッシュウォーミング)
- 41キーワード × 10回反復、7カテゴリ
- 測定値は10回平均
- Pythonベンチマークスクリプトで自動化
中間改善バージョンのクエリ構造を分析して3つのパフォーマンスボトルネック仮説を立てた:
| ボトルネック | 仮説 |
|---|---|
| A. prefixクエリ6個 | 高カーディナリティkeywordフィールドのprefixはコストが高い可能性 |
| B. function_score関数18個 | ドキュメントごとに18個の関数を全巡回 |
| C. ngramインデックスサイズ | min_gram=2, max_gram=3 → トークン数爆増 |
試行1:script_scoreで関数17個を1個に削減
最も簡単そうなものから。18個の関数のうち17個の地域優先順位termフィルタをPainlessスクリプト1つに統合した。
// Before: 17個のフィルタ
{ filter: { term: { rank: 1 } }, weight: ... }
{ filter: { term: { rank: 2 } }, weight: ... }
// ... ×17
// After: 1個のスクリプト
{ script_score: { script: "順位値基盤の加算点計算式" } }結果:±10ms。ネットワークジッター範囲内。効果なし。
OpenSearchのfilter cacheがtermフィルタの結果をbitsetでキャッシュしていたため、17個を巡回してもコストが非常に低かった。Elastic公式ドキュメントがscript_scoreを「コストの高い関数」に分類していることとも一致する結果だった。
試行2:edge_ngramでprefixクエリを置換
理論上最も確実な改善案だった。
keywordフィールドに対するprefixクエリは公式ドキュメントでもexpensive queryに分類される。540万件ならunique term数が相当なので、これがボトルネックの可能性があると仮定した。edge_ngramアナライザーでインデックス時にprefixトークンを事前生成しておけば、通常のterm lookupに変換できる。
インデックスにedge_ngram tokenizer + 6つの新フィールドを追加し、540万件を再インデキシングした(約2時間)。
結果:
| カテゴリ | prefix (ms) | edge_ngram (ms) | 差分 |
|---|---|---|---|
| 建物名正確 | 107.5 | 108.1 | +0.6 |
| 建物名短い | 108.4 | 130.7 | +22.3 |
| 道路名 | 99.4 | 109.0 | +9.6 |
| 1文字 | 112.3 | 118.8 | +6.5 |
| 全体平均 | ~101 | ~110 | +9ms(むしろ遅くなった) |
**逆効果。**edge_ngram 6つのフィールドを追加したことでインデックスサイズが増え、すべてのクエリが大きくなったインデックス上で動作するため全体的に遅くなった。
540万件規模では、prefixクエリは実際のボトルネックではなかった。
試行3:_sourceフィルタリング + クエリ構造全面転換
理論的最適化から方向を変え、実質的な転送量削減 + クエリ構造の簡素化に集中した。
変更内容:
- クエリ構造の全面転換:
function_score+bool(should)→dis_max+constant_score5-tier構造に転換。function_scoreの17地域フィルタを削除し、ソート基準を_score desc → 建物名長さ asc → 地域優先順位 ascに簡素化した。 - _sourceフィルタリング:レスポンスで実際に使用する7つのフィールドのみを返却。既存ではインデックスの全原本フィールドを返しており、検索補助用の正規化フィールドや統合テキストフィールドまで不必要に含まれてペイロードが大きかった。
- 1文字検索の最適化:1文字入力時には完全一致とprefixマッチングのみ実行するように分岐し、不要なngram/形態素マッチングをスキップする。
結果(中間改善バージョン比):
| カテゴリ | 中間改善 (ms) | 最終 (ms) | 改善率 |
|---|---|---|---|
| 建物名正確 | 107.5 | 94.9 | -12% |
| 建物名prefix | 98.2 | 88.5 | -10% |
| 建物名短い | 108.4 | 89.2 | -18% |
| 道路名 | 99.4 | 85.7 | -14% |
| 地番 | 99.7 | 89.7 | -10% |
| 1文字 | 112.3 | 67.5 | -40% |
| 全体平均 | ~101 | ~83 | -17% |
全カテゴリで一貫した改善。特に1文字検索は実行されるクエリ節が大幅に減り、40%高速化した。
7. 第2次デプロイ:最終結果(2026.04)
3段階の変遷まとめ
[第1次デプロイ] function_score + bool(should) 7節 + 8段階script sort
├── function_score: 6個の関数(重み付けベース)
├── sort: 8段階Painless script
├── ngram: なし
└── _source: 全体返却
[中間改善] function_score + bool(should) 7節
├── function_score: 18個の関数(17地域フィルタ + 1 decay)
├── sort: _score desc(script sort削除)
├── ngram: 建物名 + 住所
└── _source: 全体返却
[第2次デプロイ] dis_max + constant_score 5-tier
├── T1: 建物名完全一致 — term
├── T2: 建物名prefix — prefix
├── T3: 建物名ngram部分一致 — match(ngram)
├── T4: 形態素マッチング — match(nori)
├── T5: 住所prefix + ngram — prefix + match(ngram)
├── sort: _score desc → 建物名長さ asc → 地域優先順位 asc
├── 1文字検索時 T1, T2のみ実行
└── _source: 7フィールドのみ返却| 項目 | 第1次デプロイ | 中間改善 | 第2次デプロイ |
|---|---|---|---|
| クエリ構造 | function_score + should 7個 | function_score + should 7個 | dis_max + constant_score 5-tier |
| ソート | 8段階Painless script sort | _score desc | _score desc + フィールド2個 |
| function_score関数 | 6個 | 18個 (17+1) | 0個 |
| ngram | なし | 建物名 + 住所 | 建物名 + 住所 |
| 中間マッチング | 未対応 | 対応 | 対応 |
| _sourceフィルタリング | なし | なし | 7フィールドのみ |
| 平均レスポンス時間 | 未測定 | ~101ms | ~83ms (17%↓) |
第1次デプロイ時にはベンチマークツールがなく、正確なレスポンス時間は測定できなかった。~101msは中間改善バージョンの測定値である。
8. 教訓
理論的ボトルネック ≠ 実際のボトルネック
| 仮説 | 理論 | 実測 |
|---|---|---|
| prefix → edge_ngram | expensive queryをterm lookupに変換 | インデックスサイズ増加で逆効果 |
| 17 term → 1 script | 関数17個の巡回を排除 | filter cacheで既に高速 |
| _sourceフィルタリング + dis_max転換 | クエリ構造簡素化 + 転送量削減 | 17%の一貫した改善 |
なぜ理論と実測が異なったのか?
edge_ngramの逆効果:edge_ngramフィールドは一つの値から複数のprefixトークンを生成する。「レミアンパーク」という5文字の値から5つのトークンが生成され、これが540万件 × 複数フィールドに適用されると転置インデックスのサイズがかなり増加する。term lookupへの変換メリットよりも、大きくなったインデックスによる全般的なパフォーマンス低下の方が大きかった。
filter cacheの威力:OpenSearchはfilterコンテキストのクエリ結果をbitsetでキャッシュする。termフィルタがそれぞれキャッシュされていれば、巡回コストはbitset lookupに過ぎない。script_scoreはこのキャッシュを活用できないため、むしろメリットがなかった。
実質的なボトルネックは転送量:クエリ実行時間自体よりも、レスポンスのシリアライゼーション + ネットワーク転送に時間を取られていた。検索補助用フィールドをレスポンスから除外するだけでペイロードが大幅に削減された。
技術的教訓
-
**理論的に「確実な」改善案を盲信しないこと。**公式ドキュメントのexpensive query分類が正しくても、実際のデータとインデックス構造でボトルネックになるかどうかは測定してみなければわからない。
-
**最もシンプルなアプローチが最も効果的な場合がある。**複雑なインデックス構造変更(edge_ngram再インデキシング2時間)よりも、不要なフィールドの除去(コード数行)の方が良い結果を出した。
-
**ベンチマークツールを先に作れ。**Pythonスクリプトでベンチマークを自動化しておいたおかげで、各試行の効果を数分で定量的に確認できた。これがなければ「体感的に同じくらいかな?」で済ませていただろう。
協業における反省
技術的な教訓に劣らず大きく感じたのはコミュニケーションの重要性だ。
第1次デプロイ後、パフォーマンス改善に集中しながら様々な試行を一人で進めた。この過程で企画チーム、QAチームとの議論が非常に少なかった。パフォーマンスのために辞書順ソートを削除した部分や、全般的なソート順序の変更について、協議と周知が適切に行われなかった。
企画チームとはソートポリシー変更について合意に達したが、その内容がQAチームに共有されなかった。QAチームでは既存のソートが元の仕様だと思い、変更されたソートをバグとしてイシュー登録する事態が発生した。開発者が一人で企画と合意したからといって終わりではなく、関連するすべてのチームに変更事項が伝達されなければならないという当然の事実を見落としていた。
企画チームのソートポリシー自体も、Slack、Notionなど2〜3箇所に散在しており、整理して協議するプロセスが困難だった。今回の作業をきっかけに、企画チームにソートポリシーを一つのドキュメントに統合管理するよう要請して整理した。
技術的にどれだけ優れた改善であっても、チーム全体が変更事項を認識していなければ混乱だけが残る。この経験を通じて、協業とコミュニケーションの重要性を深く反省することになった。
実際の検索結果
最終結果はジムッサ(짐싸)アプリで直接確認できる。ngram中間マッチング、prefixマッチング、建物名 + 道路名の統合検索がすべて正常に動作している。
| 「늘채빌」検索(ngram中間マッチング) | 「노루」検索(prefixマッチング) |
|---|---|
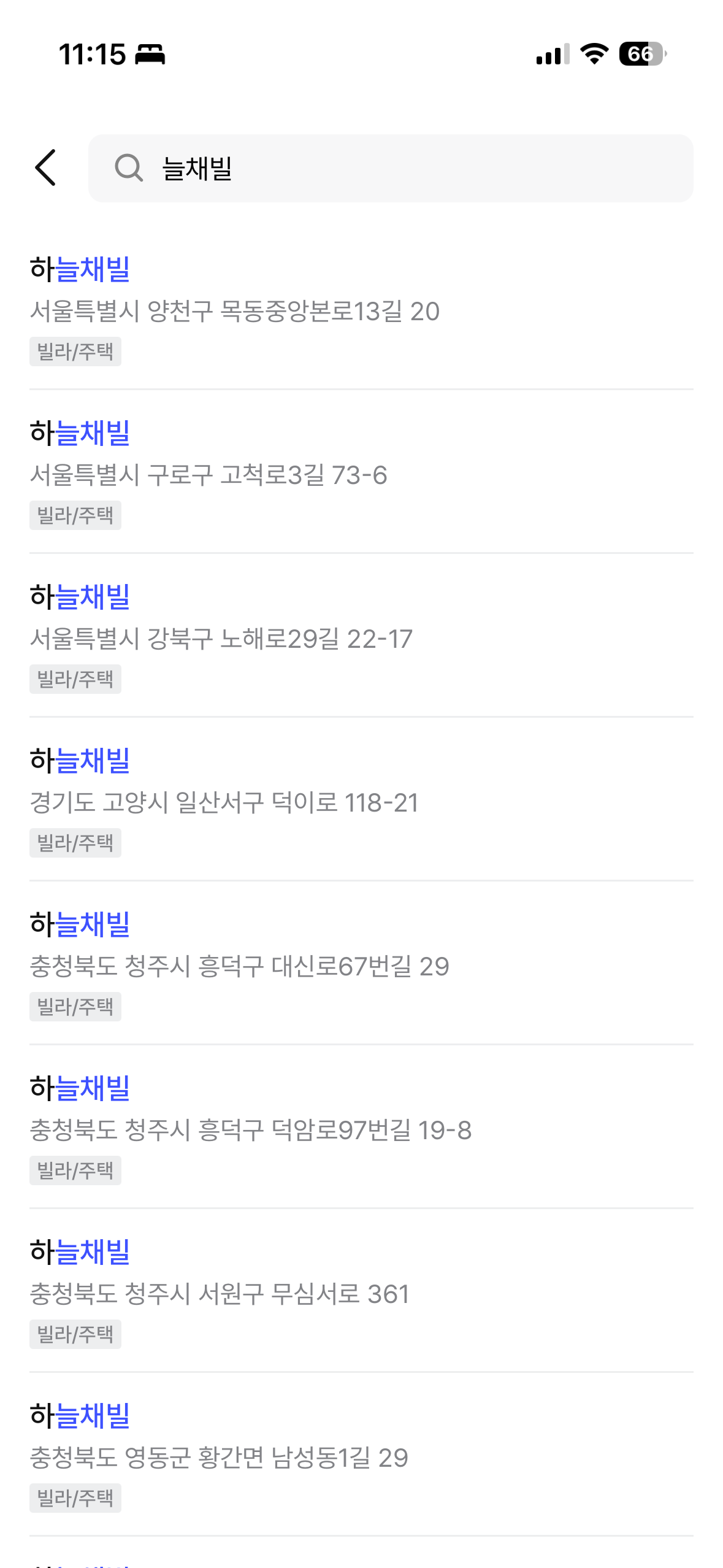 | 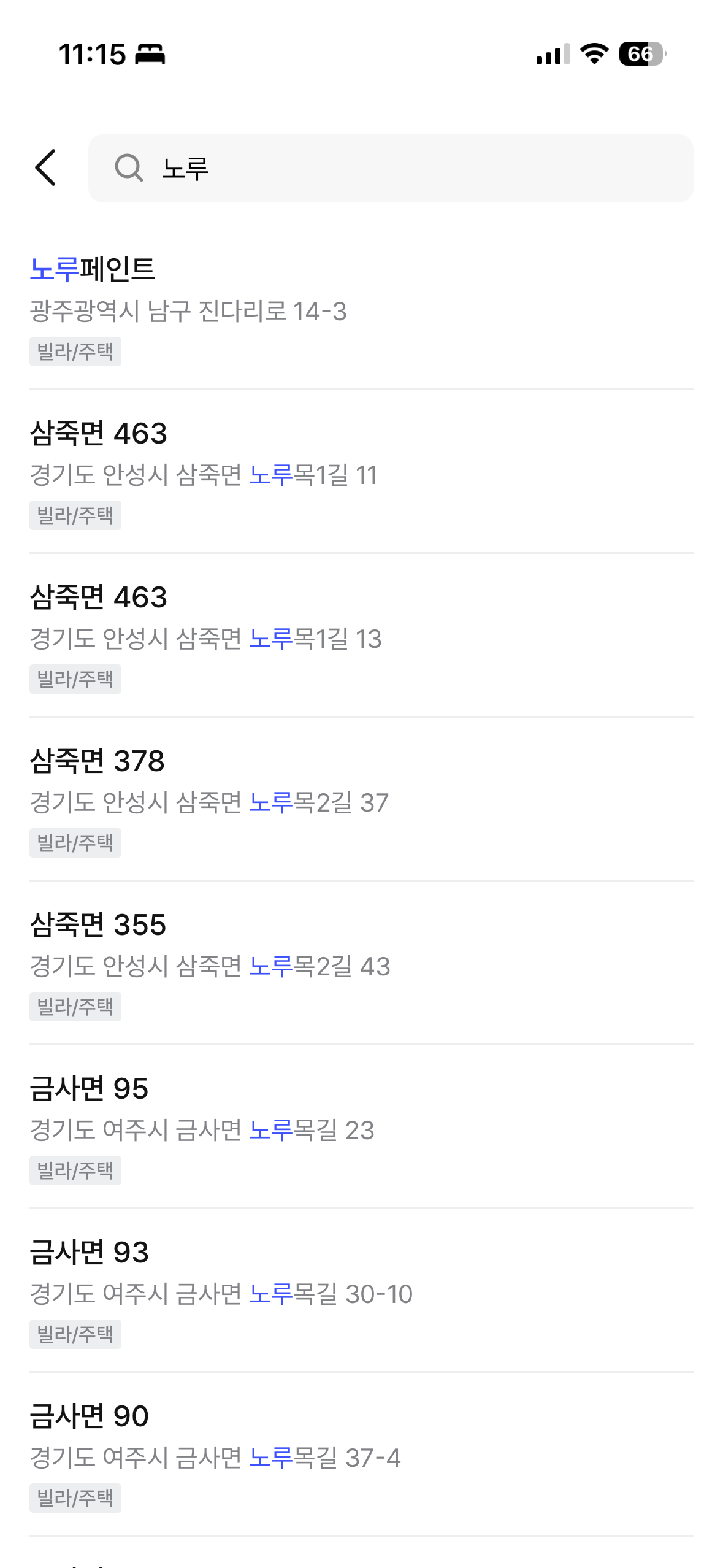 |
| 「늘채」検索(ngram中間マッチング) | 「테헤란」検索(建物名 + 道路名統合) |
|---|---|
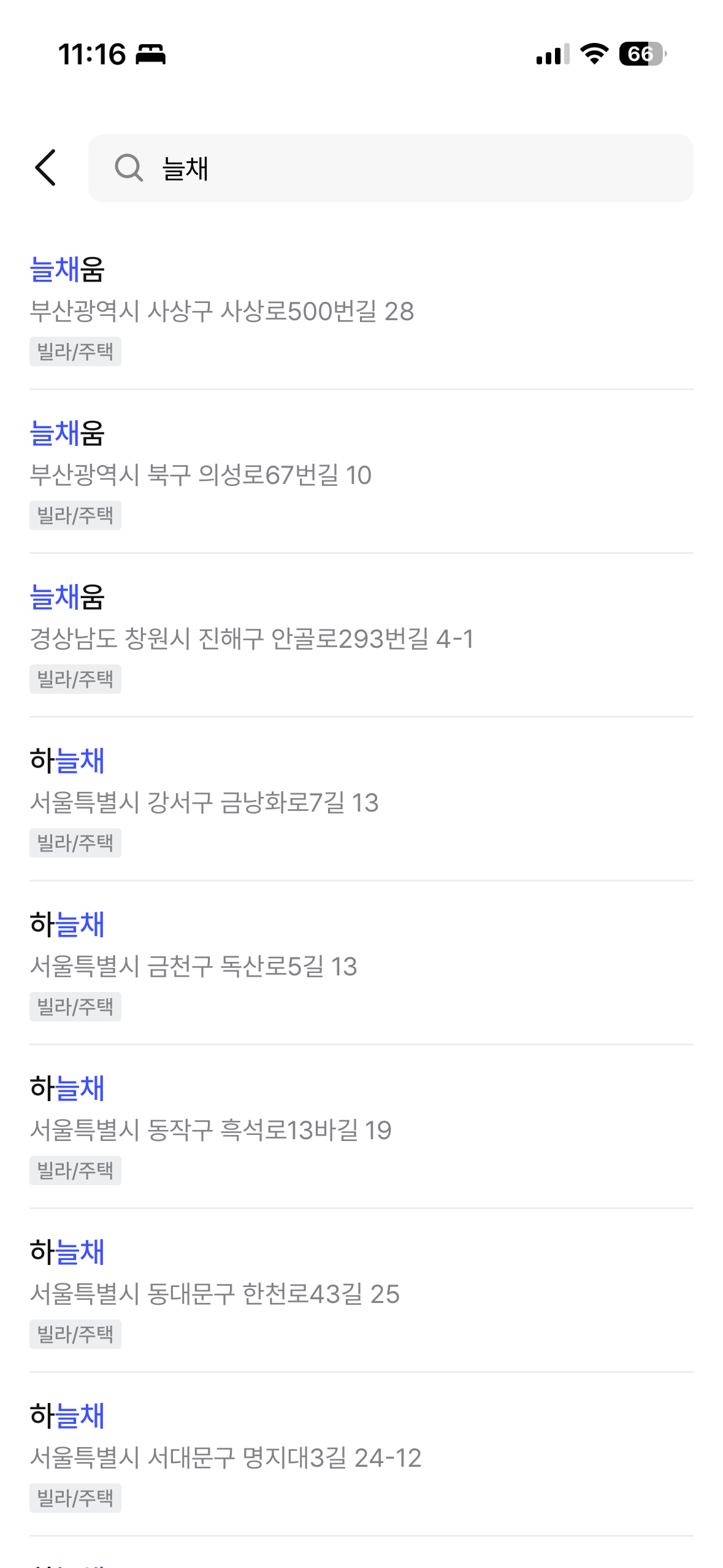 | 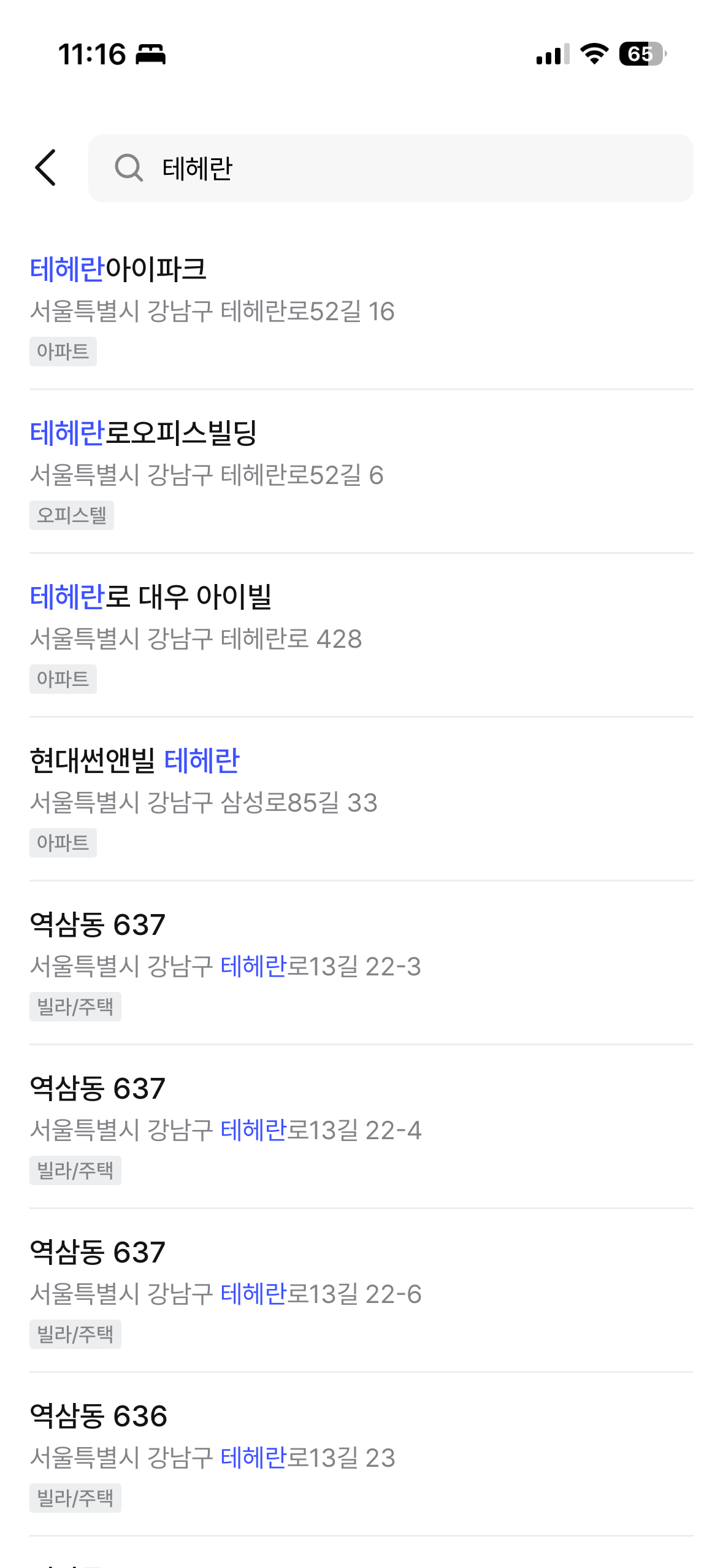 |
ジムッサアプリで直接検索してみてください。 App Store | Google Play
まとめ
83msは改善前より良くなったが、オートコンプリートの業界平均(10〜30ms)にはまだ遠く及ばない。これがベストではないことは十分認識している。キャッシュ導入、Completion Suggesterへの移行など、次のステップに進む方法を時間があるたびに調査している。AIが検索領域にも本格的に導入されている今、業界水準に追いつくためにさらに勉強し精進していく。
パフォーマンス最適化で最も重要なのは測定だ。そして測定と同じくらい重要なのは共有だ。