사내 RAG 챗봇 성능 개선기 ① — 긴 문서를 어떻게 잘라야 검색이 잘 될까
목차
사내 RAG 챗봇 성능 개선기 (3부작)
- 긴 문서를 어떻게 잘라야 검색이 잘 될까 — 청킹 전략 3차 재설계 ← 지금 읽는 글
- 유사도 0.72 vs 임계값 0.75 — RAG가 아는 답을 못 찾을 때 (근일 공개)
- 벡터DB 교체기 — Chroma 대신 Qdrant를 고른 이유 (근일 공개)
짐싸에서는 Claude, Codex 같은 AI 도구를 전사적으로 도입해 모든 임직원이 업무에 활용하고 있다. 그 흐름 속에서 사내 위키 문서를 기반으로 답변하는 RAG 챗봇 "시루AI"도 Slack에서 계속 다듬고 있다. 아직 회사 전체에 정식 배포된 건 아니고, 백엔드팀 안에서 제한적으로 테스트하며 다듬는 단계다.
이 시리즈는 그 시루AI의 RAG 파이프라인을 다듬으며 겪은 일들의 기록이다. 첫 편의 주제는 파이프라인의 가장 앞단, 청킹(chunking)이다.
1. 왜 문서를 통째로 넣지 않는가
RAG(Retrieval-Augmented Generation)는 질문이 들어오면 지식베이스에서 관련 부분을 찾아 LLM 프롬프트에 끼워 넣는 방식으로 동작한다. 이때 문서를 통째로 임베딩(벡터화)하지 않고 작은 단위로 잘라서 각각 벡터화하는 이유는 간단하다. 문서 하나에 여러 주제가 섞여 있으면, 그 문서 전체를 하나의 벡터로 뭉뚱그렸을 때 벡터가 "평균적인 의미"로 희석되어 정작 필요한 부분과의 유사도가 떨어진다. 예를 들어 휴가 정책과 배포 절차가 한 문서에 같이 담겨 있으면, 배포 관련 질문에도 휴가 문서의 의미가 함께 섞여 들어간다. 그래서 문서를 청크(chunk) 단위로 쪼개고, 각 청크를 독립적으로 검색 대상에 넣는다.
문제는 "얼마나 잘게 쪼갤 것인가"다. 너무 잘게 쪼개면 문맥이 끊기고, 너무 크게 쪼개면 앞서 말한 희석 문제가 재발한다. 시루AI의 청킹 로직은 이 균형점을 세 차례에 걸쳐 다시 잡아야 했다.
미리 말해두면, 이번 개선의 목표는 답변 품질을 튜닝하는 게 아니라 검색 대상 자체가 빠지지 않게 만드는 것이었다.
2. 1차: 글자 수 기준으로 시작하다
처음 구현은 단순했다. 800자 단위로 자르고, 청크 사이 120자를 겹치게(overlap) 했다. 겹침을 두는 이유는 청크 경계에서 문맥이 뚝 끊기는 걸 막기 위해서다 — 예를 들어 한 문장이 청크 경계에 걸쳐 있으면, 겹치는 구간 덕에 다음 청크에서도 그 문장이 온전히 남는다.
글자 수 기준은 구현이 쉽고 예측 가능하다는 장점이 있다. 실제로 한동안 이 방식으로 잘 돌아갔다. 문제는 "글자 수"와 "임베딩 모델이 실제로 처리하는 단위(토큰)"가 서로 다른 척도라는 데서 시작됐다.
3. 첫 번째 장애 — 임베딩 서버가 청크를 거부하다
어느 날 재인덱싱 로그를 보다가 이상한 걸 발견했다. 임베딩 서버 에러 로그에 이런 메시지가 쌓여 있었다.
input (530 tokens) is too large to process.
increase the physical batch size (current batch size: 512)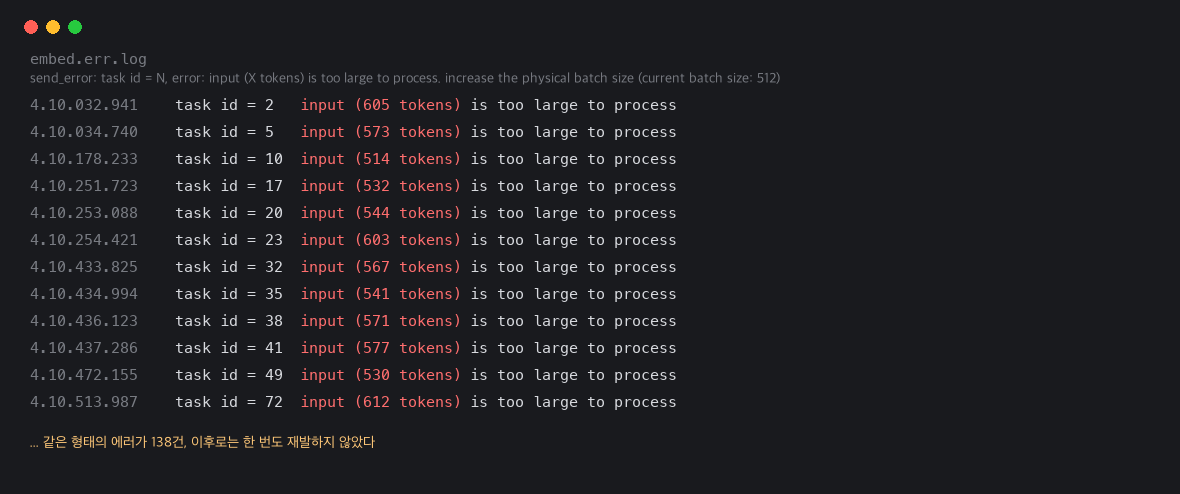
임베딩 서버(nomic-embed 모델을 얹은 llama.cpp 서버)의 컨텍스트 크기는 2048로 넉넉하게 잡아뒀는데도 청크가 거부당하고 있었다. 나중에 알고 보니 컨텍스트 크기와 이 거부의 진짜 원인은 서로 무관한 별개의 제한이었다. 로그를 더 뒤져보니 거부당한 입력의 토큰 수는 514토큰부터 600토큰을 훌쩍 넘는 것까지 제각각이었다. 똑같이 "800자"로 잘랐는데도 어떤 청크는 통과하고 어떤 청크는 실패했다는 뜻이다. 800자가 왜 이렇게 많은 토큰으로 변했는지는 뒤에서 다시 짚는다.
더 큰 문제는 이 예외 처리였다. 실패하면 except: print(...); continue로 조용히 넘어가도록 짜여 있었는데, 당시 다른 작업들과 병행하느라 컨텍스트 스위칭이 잦았던 탓에 이 예외 경로를 놓쳤다. 그 대가로 눈에 띄는 실패 신호 없이 해당 청크 4개만 색인에서 조용히 빠진 채 몇 주가 지났다(앞서 로그의 138건은 디버깅 중 반복 실행한 재인덱싱 시도들이 겹쳐 쌓인 기록이고, 실제로 최종까지 빠져 있던 건 이 4개였다). 위키에 분명히 있는 내용인데 봇이 "관련 정보가 없다"고 답하는 일이 있다면 이런 조용한 결손이 원인일 수 있다.

오진단 — 배치 크기를 착각하다
원인은 명확해 보였다. "배치 크기가 기본값(512)으로 설정된 채 안 바뀐 것 같다"고 판단하고, 서버 실행 옵션에 --batch-size 2048을 추가한 뒤 재시작했다. 그런데 같은 입력으로 재현 테스트를 돌려보니 여전히 실패했다. 에러 메시지의 current batch size: 512도 그대로였다.
재진단 — logical과 physical은 다른 파라미터다
--help 출력을 다시 찬찬히 읽어보고서야 착각을 발견했다. llama-server에는 서로 다른 두 개의 배치 크기 옵션이 있다.
-b, --batch-size(logical batch size, 기본값 2048)-ub, --ubatch-size(physical batch size, 기본값 512)
두 값의 역할은 이렇게 다르다.
- logical batch (
-b): 서버가 여러 요청을 모아 한꺼번에 스케줄링할 수 있는 토큰 수의 상한. 여러 요청을 큐에 쌓아두는 단위에 가깝다. - physical batch / micro-batch (
-ub): 실제로 GPU/CPU가 한 번의 연산으로 처리하는 토큰 수. logical batch가 이보다 크면, 서버가 내부적으로 이 크기만큼 잘게 쪼개서 순차적으로 돌린다. 시퀀스 길이가 길어질수록 어텐션 연산에 필요한 메모리가 늘어나기 때문에, 하드웨어가 감당할 수 있는 단위를 이 값으로 별도 통제하는 것이다.
결론부터 말하면, 임베딩 요청 하나(청크 하나)가 physical batch 크기를 넘으면 알아서 쪼개져 처리되는 게 아니라 통째로 거부된다. 그 요청은 애초에 단 한 번의 물리 연산 단위에도 담기지 않기 때문이다. --batch-size(logical)를 아무리 올려도 요청을 더 많이 큐에 쌓을 수 있게 될 뿐, 개별 요청이 물리 연산 단위 하나에 들어가야 한다는 제약(--ubatch-size)과는 무관했다. 그래서 처음 시도는 애초에 문제를 건드리지도 못했던 것이다. 에러 메시지의 "physical batch size"는 후자를 가리키는 것이었다. --ubatch-size는 그대로 512에 머물러 있었으니 실패가 반복될 수밖에 없었고, 옵션 두 개를 모두 2048로 맞추고 나서야 해소됐다.
--batch-size 2048 --ubatch-size 2048수정 후 이전에 실패했던 청크들을 다시 돌려 실패 0건을 확인하고, 전체 재인덱싱(93초, 2806청크, 실패 0)으로 마무리했다. 서버 설정 문제는 해결됐지만, 애초에 왜 800자 청크가 512토큰을 넘었는지는 아직 남아 있었다.
4. 2차 재설계 — 글자 수에서 토큰 수로
사실 그전까지는 글자 수와 토큰 수가 다르다는 걸 어렴풋이만 알고 있었다. 다만 깊이 파고들지 않아서, 512라는 토큰 제한이 실제로 청크를 통째로 거부시킬 수 있다는 것까지는 생각이 미치지 못했다. 800자라는 청크 크기 자체도 별다른 근거 없이 정한 숫자였다. 응급 복구를 마친 뒤에야 "글자 수와 토큰 수가 왜 이렇게 차이가 나는가"를 들여다보기 시작했다. 그 과정에서 llama-server가 /tokenize라는 엔드포인트를 기본 제공한다는 것도 알게 됐다 — 임베딩 모델이 실제로 쓰는 토크나이저와 동일한 기준으로 텍스트를 토큰 단위로 직접 확인할 수 있는 엔드포인트다.
한글이 토큰을 더 많이 먹는다
한글이 영어보다 토큰을 더 많이 먹는다는 방향성 자체는 알고 있었다(그래서 평소 사내 스킬 문서도 영어로 작성해왔다). 여기에 마크다운 표에 많이 쓰이는 특수문자까지 겹치면 더 심해질 거라 예상은 했지만, 정확히 얼마나 차이가 나는지는 감으로 잡을 수 있는 수준이 아니었다. /tokenize로 직접 재봤다.
| 텍스트 | 글자 수 | 토큰 수 | 글자당 토큰 |
|---|---|---|---|
hello (영문) | 5 | 1 | ~0.2 |
할렐루야 (한글) | 4 | 4 | ~1.0 |
이 샘플만 봐도 한글은 영어보다 글자당 토큰 소비량이 확연히 컸다 — hello는 1토큰(글자당 ~0.2)인데 할렐루야는 4토큰(글자당 ~1.0), 글자당 토큰 소비량으로 보면 5배 차이다. 단어 하나씩 비교한 예시라 그대로 일반화할 수는 없지만, 방향성만큼은 앞서 본 실제 실패 사례들(514~600+ 토큰)이 뒷받침한다. 임베딩 모델의 토크나이저 어휘가 영어 텍스트에 더 효율적인 경우가 많다 보니, 영어는 여러 글자를 토큰 하나로 묶어 처리하지만 한글은 훨씬 잘게 쪼개진다. 이래서 800자짜리 청크가 문서 내용에 따라 514토큰짜리도 되고 600토큰이 넘는 것도 됐던 것이다. 실제 위키 청크 15개를 무작위로 뽑아 같은 방식으로 재보니, 글자당 토큰은 평균 0.53개(범위 0.36~0.65)로 나왔다 — 영어(약 0.2)보다는 확실히 높고 순수 한글(약 1.0)보다는 낮은, 한글·영어·마크다운 문법이 뒤섞인 실제 문서다운 값이다.
실패한 청크 중 가장 아슬아슬했던 사례를 하나 재현해봤다. 본문 509토큰에 임베딩 프리픽스(search_document: — nomic 계열 임베딩 모델이 문서용 임베딩과 질문용 임베딩(search_query: )을 구분하도록 붙이는 고정 접두어) 4토큰이 더해져 정확히 513토큰 — 한도였던 512를 딱 1토큰 초과한 상태였다. 600토큰을 훌쩍 넘겨 실패한 청크들과 달리, 이 사례는 "1토큰 차이로 통째로 거부당한다"는 걸 보여준다. 애초에 글자 수라는 척도로는 절대 예측할 수 없는 실패였다.
이분탐색으로 청크 경계 찾기
결론은 명확했다. 글자 수가 아니라 토큰 수를 기준으로 청크를 잘라야 한다. 청크 본문의 목표 토큰 수는 500으로 정했다(임베딩 프리픽스 4토큰은 본문과 별도로 뒤에 더 붙는다). --ubatch-size 2048 설정은 응급 복구 이후에도 그대로 유지했으니, 이제 서버가 500토큰짜리 청크를 거부할 일은 없다. 그런데도 목표를 2048 근처가 아니라 훨씬 낮은 500으로 잡은 핵심 이유는 검색 품질이다.
내가 참고한 여러 RAG 구현 사례에서도 비슷한 경험적 범위가 흔히 언급된다. 사실 검색·FAQ성 문서는 100~500토큰, 서술형·설명형 문서는 500~1000토큰 정도가 흔히 인용되는 범위다. 시루AI의 위키 문서는 절차·정책처럼 사실 확인성 내용이 많아 전자에 가깝고, 500은 그 범위의 상한에 해당한다. 이 범위의 원리는 트레이드오프 하나로 요약된다 — 청크 하나가 하나의 완결된 주제를 담을 만큼은 커야 하고(너무 작으면 맥락이 조각난다) 여러 주제가 섞이지 않을 만큼은 작아야 한다(너무 크면 유사도 검색이 무뎌진다).
여기에 원래 기본값(512) 대비 안전 마진이라는 보조적인 이유도 있다. 프리픽스 4토큰을 더해도 508(512−4)보다 8토큰 낮은 500이면, --ubatch-size가 나중에 다시 기본값 512로 돌아가더라도 안전하다.
청크 경계를 다음 방식으로 찾도록 재설계했다.
def find_chunk_end(text, start, target_tokens):
lo, hi = start, len(text)
while lo < hi:
mid = (lo + hi + 1) // 2
if count_tokens(text[start:mid]) <= target_tokens:
lo = mid
else:
hi = mid - 1
return lo전체 텍스트를 앞에서부터 하나씩 토큰화하며 확인하는 대신, 이분탐색(binary search)으로 "본문 500토큰 이하"를 만족하는 가장 긴 구간을 O(log n) 번의 /tokenize 호출로 찾는다. 실제 임베딩 호출 전에 토큰 수를 먼저 확인하니, 잘못된 요청으로 서버가 거부당하는 일 자체가 원천 차단됐다.
다음 청크의 시작 위치는 이전 청크가 끝난 자리에서 그대로 이어지지 않고, 오버랩만큼 뒤로 물러난 지점에서 시작한다. 오버랩 자체는 앞서 나온 800자/120자 설계 때와 마찬가지로 지금도 글자 수 기준(120자)이다 — 청크 크기를 정하는 목표치만 토큰 기준으로 바뀌었을 뿐, 오버랩 계산은 그대로 글자 단위로 남겨뒀다. 그런데 청크 하나의 길이 자체가 남은 텍스트 양에 따라 들쭉날쭉해지다 보니(문서 끝에 가까울수록 채울 텍스트가 적어 청크가 짧아진다), "청크 길이 − 오버랩"으로 정해지는 다음 청크까지의 전진 폭도 청크 길이를 따라 같이 줄어들었다.
이 과정에서 버그도 하나 잡았다. 문서 끝부분처럼 청크 길이가 오버랩과 비슷하거나 그보다 작아지면, 전진 폭이 아주 좁아지거나 심하면 한 글자 수준까지 쪼그라들었다. 예를 들면 이런 식이다(문서가 1850번째 글자에서 끝난다고 가정).
청크 A: 1200 ~ 1800번째 글자
청크 B: 1600 ~ 1850번째 글자 (문서 끝에 도달)
청크 C: 1601 ~ 1850번째 글자 ← 1글자만 전진, B와 거의 동일
청크 D: 1602 ~ 1850번째 글자 ← 또 1글자만 전진, C와 거의 동일
..."청크가 이미 문서 끝에 닿았으면 거기서 멈춘다"는 조건이 빠져 있던 게 원인이었다 — 그 조건 하나를 추가해 해결했다. 재설계 후 전체 재인덱싱을 돌려 123초, 2071청크, 목표 토큰 수를 초과하는 청크 0개를 확인했다.
5. 3차 개선 — 헤더를 무시하면 생기는 문제
토큰 기준으로 바꾸고 나서도 남은 문제가 두 가지 있었다. 첫째, 순수하게 토큰 수만 보고 자르다 보니 마크다운 헤더(##, ###)로 구분된 서로 다른 주제가 한 청크에 섞였다 — 같은 500토큰 안에 서로 다른 주제가 섞이면, 벡터는 다시 1장에서 설명한 "여러 주제의 평균"으로 희석된다. 둘째, 긴 섹션을 다시 쪼갤 때 자연스러운 경계를 보지 않다 보니 최악의 경우 단어 중간에서 잘리는 일이 생겼다.
해결 순서는 이렇다.
split_by_headers()—##/###기준으로 먼저 섹션을 나눈다.merge_small_sections()— 100토큰 미만의 너무 작은 섹션은 다음 섹션과 합친다(제목만 있고 본문이 짧은 섹션이 그 자체로 단독 청크가 되는 걸 막기 위한 하한이다).- 그래도 섹션이 500토큰을 넘으면
split_oversized()로 보조 분할한다.
자연스러운 경계 찾기
split_oversized()가 실제로 보조 분할을 어떻게 수행하는지 코드로 보면 이렇다.
def split_oversized(section, target_tokens, overlap):
chunks, i, n = [], 0, len(section)
while i < n:
hard_end = find_chunk_end(section, i, target_tokens)
end = find_natural_break(section, i, hard_end) if hard_end < n else hard_end
chunks.append(section[i:end])
if end >= n:
break
i = max(i + 1, end - overlap)
return chunks동작 순서는 이렇다.
find_chunk_end(3장에서 나온 이분탐색)로 "목표 토큰 수(500)를 안 넘는 가장 먼 지점"을 기계적으로 찾는다.- 그 지점이 섹션의 끝이 아니라면
find_natural_break로 최대 200자 뒤로 거슬러 올라가며 더 자연스러운 경계를 찾는다. 이미 섹션 끝이라면 다듬을 필요가 없으니 그대로 쓴다. - 그 구간을 청크로 저장한다.
- 섹션 끝에 도달했으면(
end >= n) 즉시 멈춘다 — 이게 앞서 나온 축퇴 루프 버그의 수정 지점이다. - 아니라면 오버랩만큼 물러난 지점에서 다음 청크를 시작하되, 최소 1글자는 반드시 전진하도록(
max(i + 1, ...)) 강제한다.
find_natural_break()는 2번 단계에서 목표 지점 200자 이내를 역방향으로 훑으며 다음 우선순위로 경계를 찾는다. 200자라는 값 자체에 정교한 근거가 있는 건 아니다 — 너무 좁으면 자연스러운 경계를 못 찾는 경우가 늘고, 너무 넓으면 목표 토큰 수에서 크게 벗어난 지점까지 되돌아가게 되니 그 사이에서 잡은 값이다.
줄바꿈 → 문장 끝(. ! ?) → 쉼표/공백 → (없으면) 기존 토큰 경계로 폴백이 네 단계는 의도적으로 계층을 나눈 것이다. 줄바꿈과 문장끝은 되도록 지키고 싶은 상위 우선순위라 탐색 범위를 그대로 두고, 쉼표·공백은 그 둘 다 실패했을 때만 작동하는 최후 안전망으로 한 단계 아래에 배치했다. 이렇게까지 하고 나니 단어 중간 절단은 200자 룩백 범위 안에 공백이 단 하나도 없는 특수한 경우(예: 200자를 넘는 URL 하나만 덩그러니 있는 경우)에만 남았고, 실사용에서는 사실상 발생하지 않는다.
헤더 레벨은 ###까지 포함하기로 했다. 위키 문서 중 일부는 ##만 쓰고 일부는 ##과 ###을 중첩해서 쓰는데, 후자를 제대로 나누려면 ###까지 봐야 했다. 최종 검증은 전체 재인덱싱 두 차례(환경 차이로 시간은 178초 / 101초로 달랐지만, 둘 다 3245청크·실패 0건)로 마쳤다.
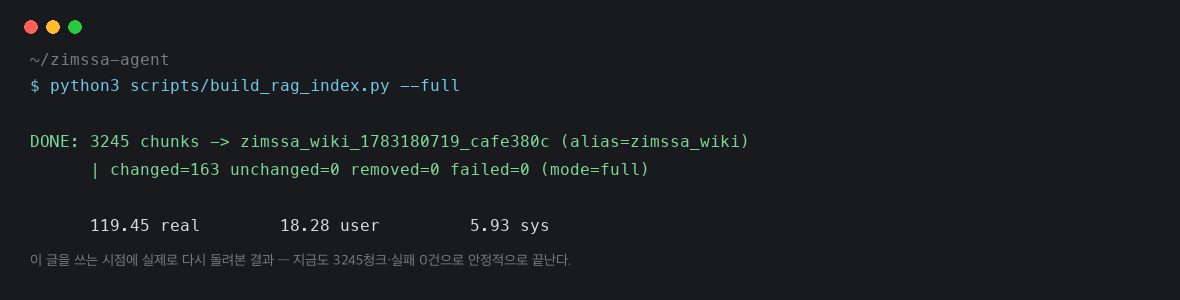
청크 수는 2071에서 3245로 늘었다. 이제 100토큰 미만의 작은 섹션만 병합되고, 나머지는 토큰 한도와 무관하게 헤더 하나당 최소 하나의 청크로 나뉘기 때문이다 — 이전에는 여러 헤더 섹션이 500토큰 한도 안에서 한 청크로 뭉치는 경우가 많았다. 그렇다고 비용이나 성능 부담이 커지지는 않았다. nomic-embed는 로컬 llama.cpp 서버에서 직접 서빙하는 모델이라 청크가 늘어도 별도 API 비용이 없고, 인덱싱 시간도 178초/101초로, 이전 123초보다 늘긴 했지만 운영 부담으로 볼 정도는 아니었다.
6. 결과와 교훈
| 단계 | 기준 | 결과 |
|---|---|---|
| 1차 | 800자 + 120자 오버랩 | 514~600+ 토큰짜리 일부 청크가 physical batch 한도 초과로 거부·누락 |
| 2차 | 토큰 기준 이분탐색(목표 500) | 123초, 2071청크, 목표 초과 청크 0개 |
| 3차 | 헤더 우선 분할 + 자연 경계 탐색 | 178초/101초, 3245청크, 실패 0건 |
800자 고정 → 토큰 기준 이분탐색 → 헤더 우선 분할까지, 세 번의 재설계를 거치며 청킹 로직은 처음보다 훨씬 복잡해졌다. 대신 "조용히 몇 주씩 결손 나는" 종류의 사고는 사라졌고, 단어 중간 절단도 실사용 범위에서는 없는 수준까지 줄었다.
이 과정에서 얻은 교훈은 세 가지다.
첫째, 초기값은 근거가 있어야 나중에 고치기 쉽다. 800자·120자 오버랩은 별다른 근거 없이 잡은 숫자였고, 그래서 문제가 터졌을 때 "왜 하필 800이었지"부터 다시 따져야 했다. 반대로 재설계한 500토큰은 원래 기본값(512) 대비 안전 마진과 업계의 경험적 범위라는 두 가지 근거를 갖고 있어서, 나중에 문제가 생겨도 어느 지점을 조정해야 할지 바로 판단할 수 있다.
둘째, 파라미터 이름이 비슷하다고 같은 걸 가리키는 건 아니다. --batch-size와 --ubatch-size를 헷갈려서 첫 번째 응급 조치가 허탕을 쳤다. 에러 메시지의 단어(physical)만 보고 넘겨짚지 않고 --help 문서를 다시 찬찬히 읽고 나서야 진짜 원인을 찾았다.
셋째, AI가 짠 코드는 정상 경로만큼 예외 처리 경로도 봐야 한다. 실패 시 조용히 넘어가는 except 블록 하나가 몇 주간의 조용한 검색 결손으로 이어졌다.
가장 중요했던 건 사실 코드가 아니었다. 이분탐색 방식을 쓸지, 목표 토큰 수를 얼마로 잡을지, 프리픽스를 토큰 수에 포함할지, 헤더 레벨을 어디까지 볼지 — 이런 설계 판단은 전부 직접 정했고, 코드 구현만 AI에게 맡겼다. 이 구분이 꽤 중요했는데, 다음 편에서 다룰 사건에서는 정반대로 판단 자체를 AI에게 맡겼다가 문제를 놓친 경험을 하게 된다.
이번 글에서 다룬 개선은 검색 정답률이 아니라 색인 결손과 청크 무결성 문제를 해결한 것이었다 — 청크가 빠짐없이 색인되고 문서 경계를 지키게 만드는 일과, 실제 질문에 대한 검색 정답률이 오르는 일은 별개의 문제다.
청킹을 이렇게까지 다듬었는데도, 여전히 풀리지 않는 검색 실패가 하나 남아있었다. 정답률 문제는 다음 편에서 다룬다.